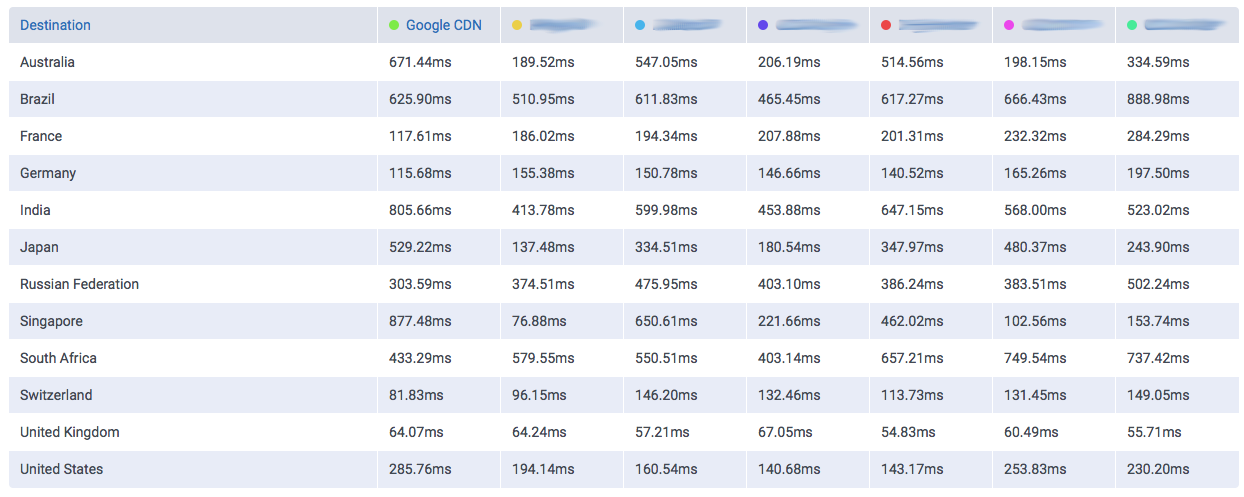
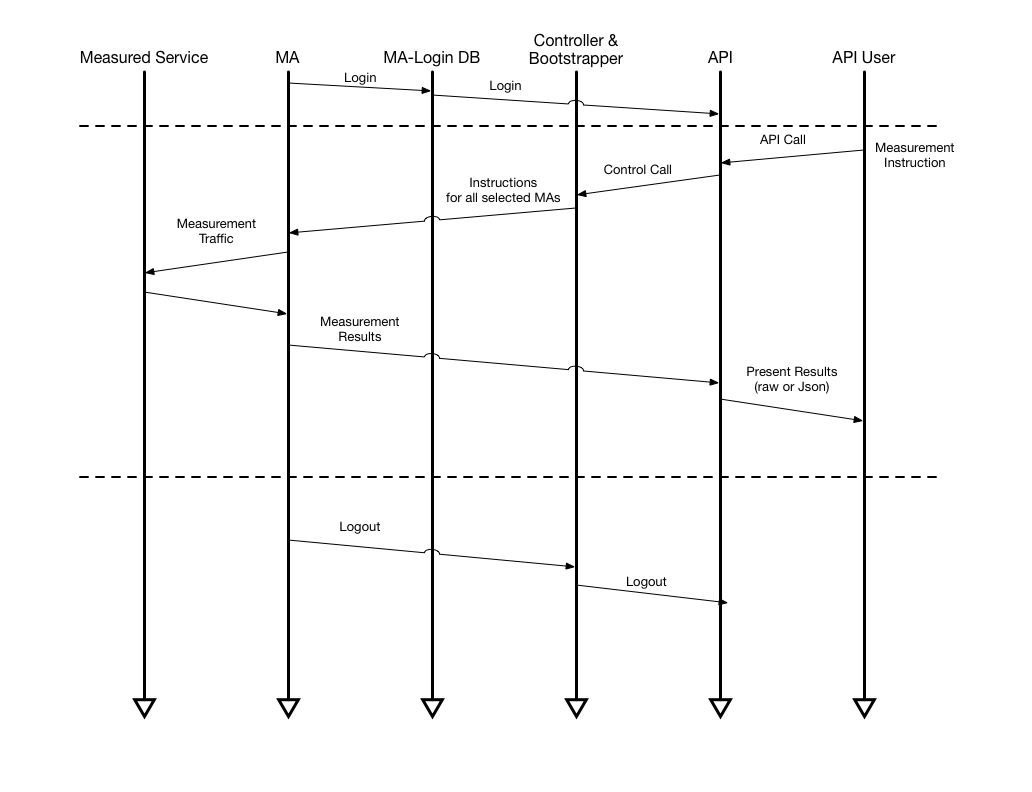
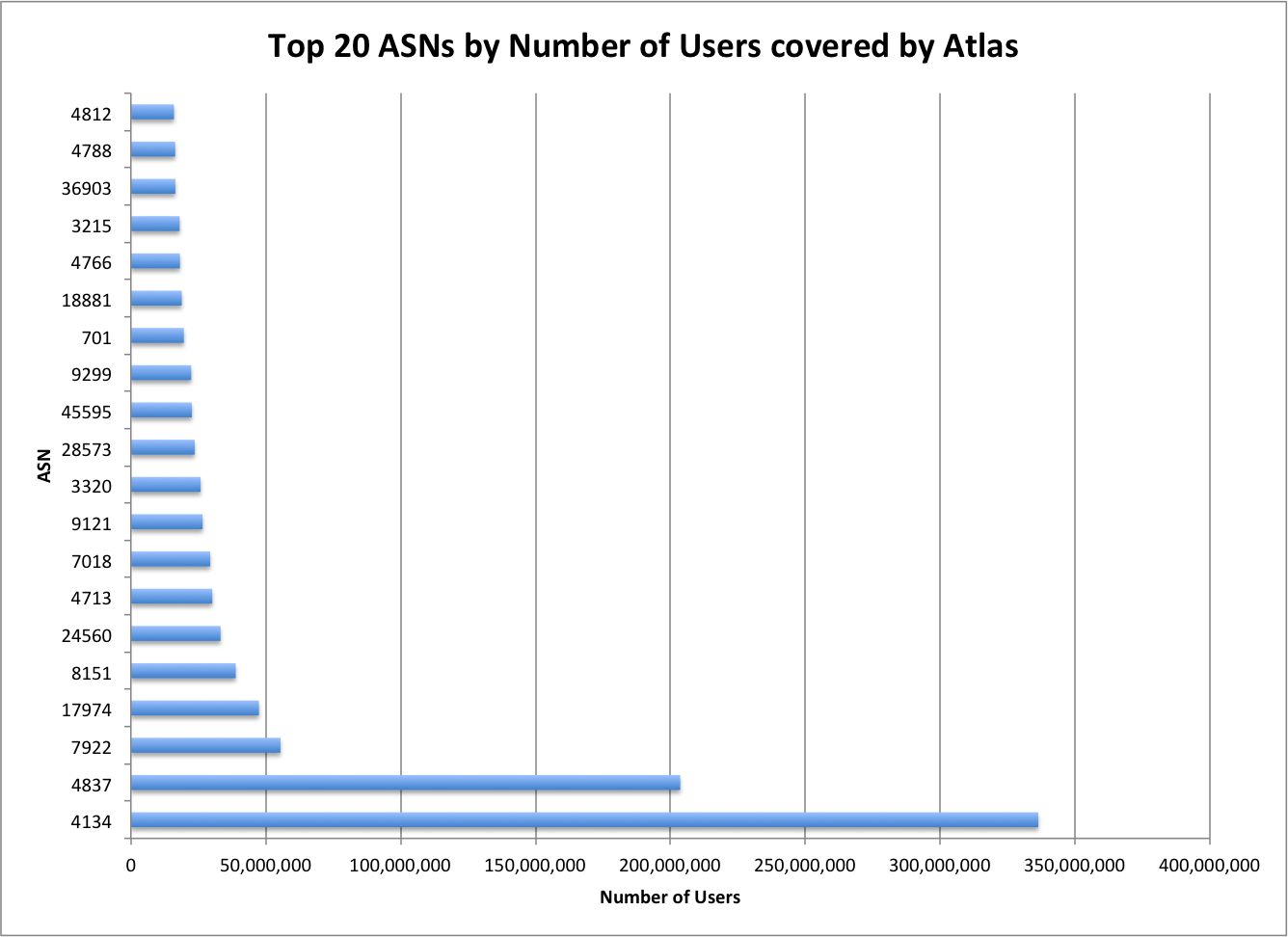
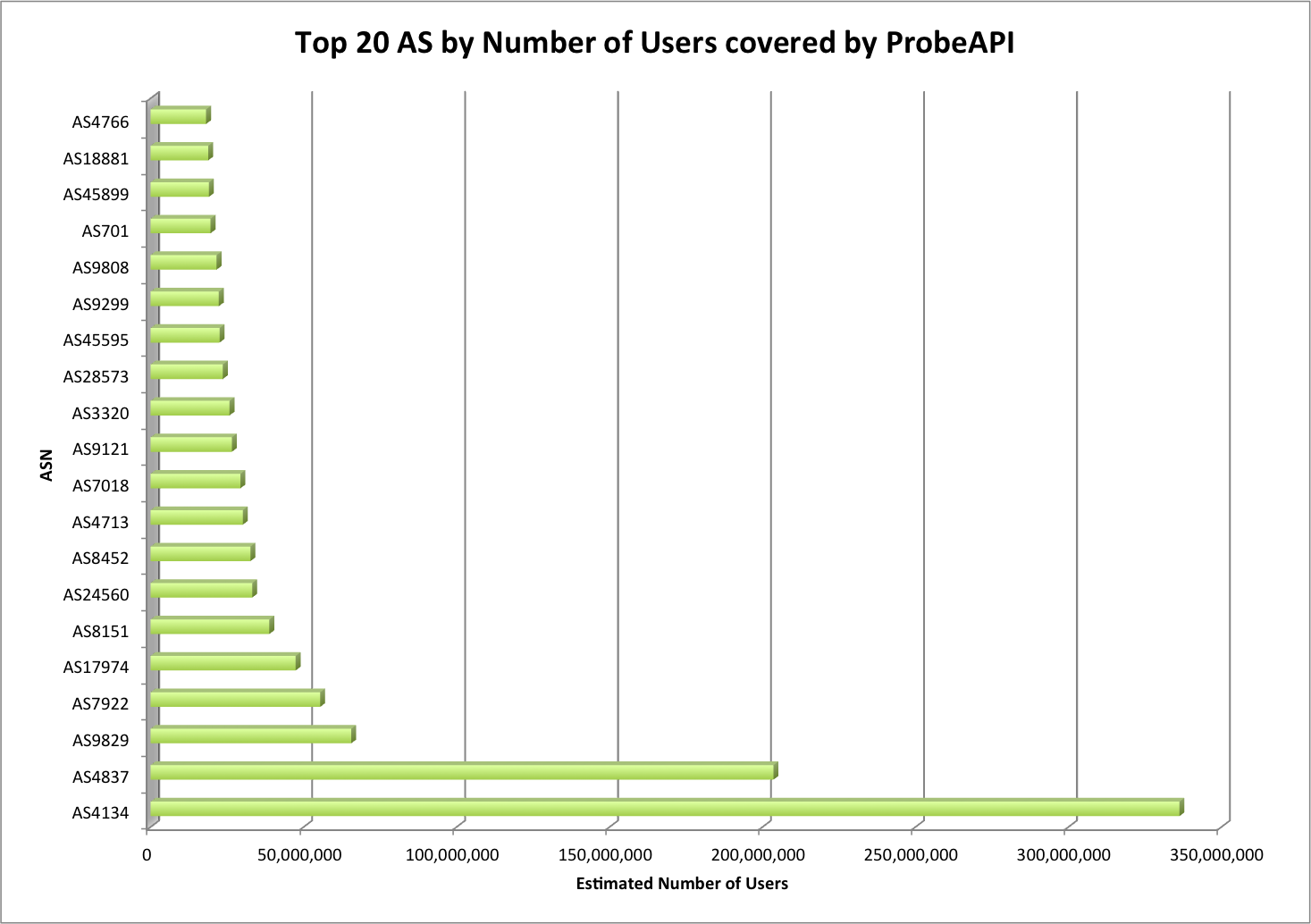
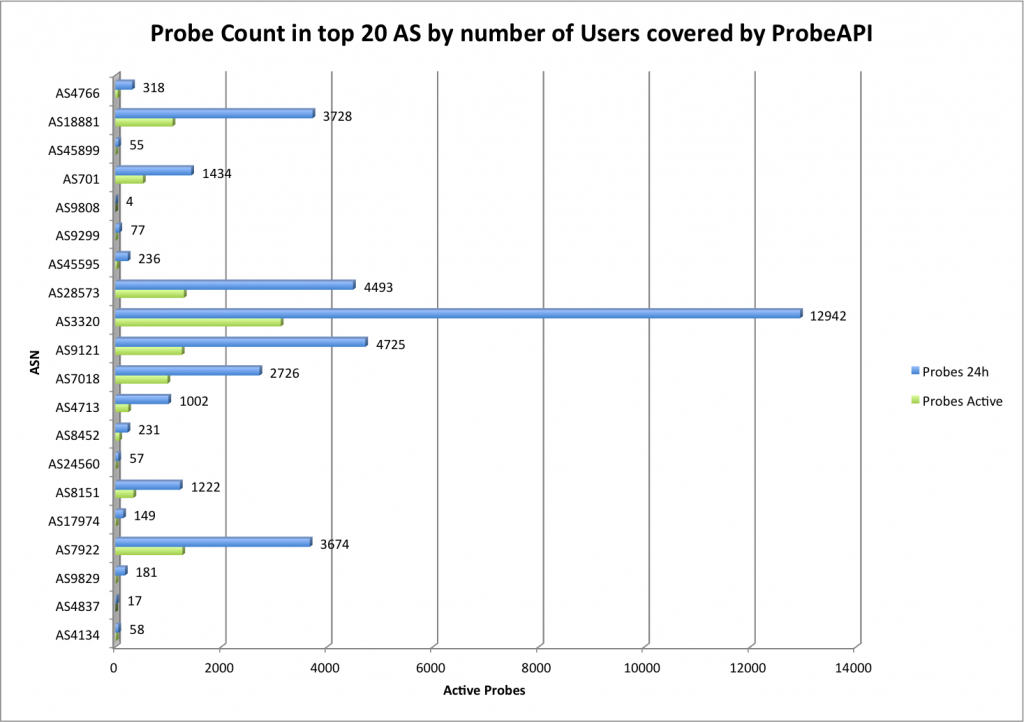
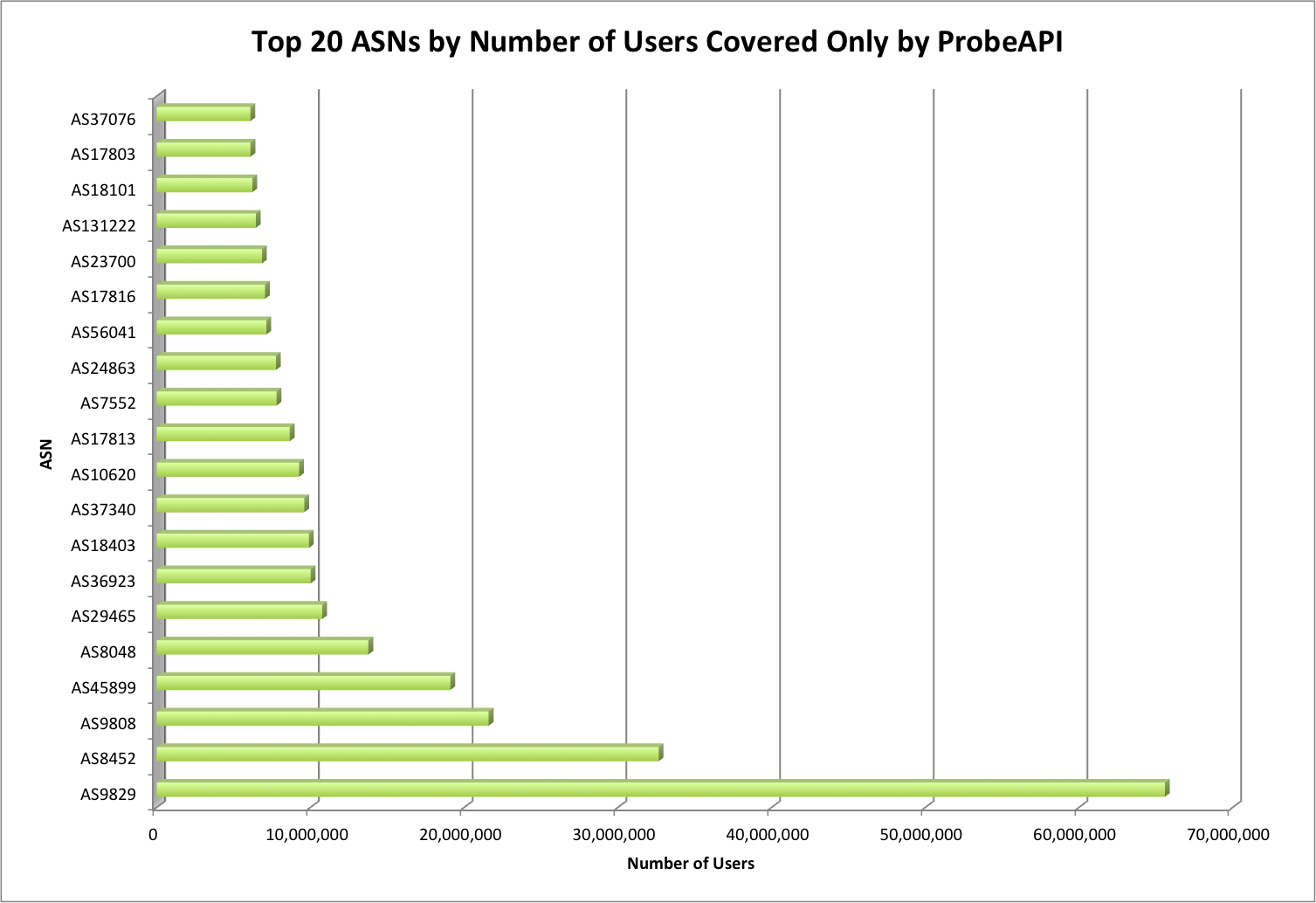
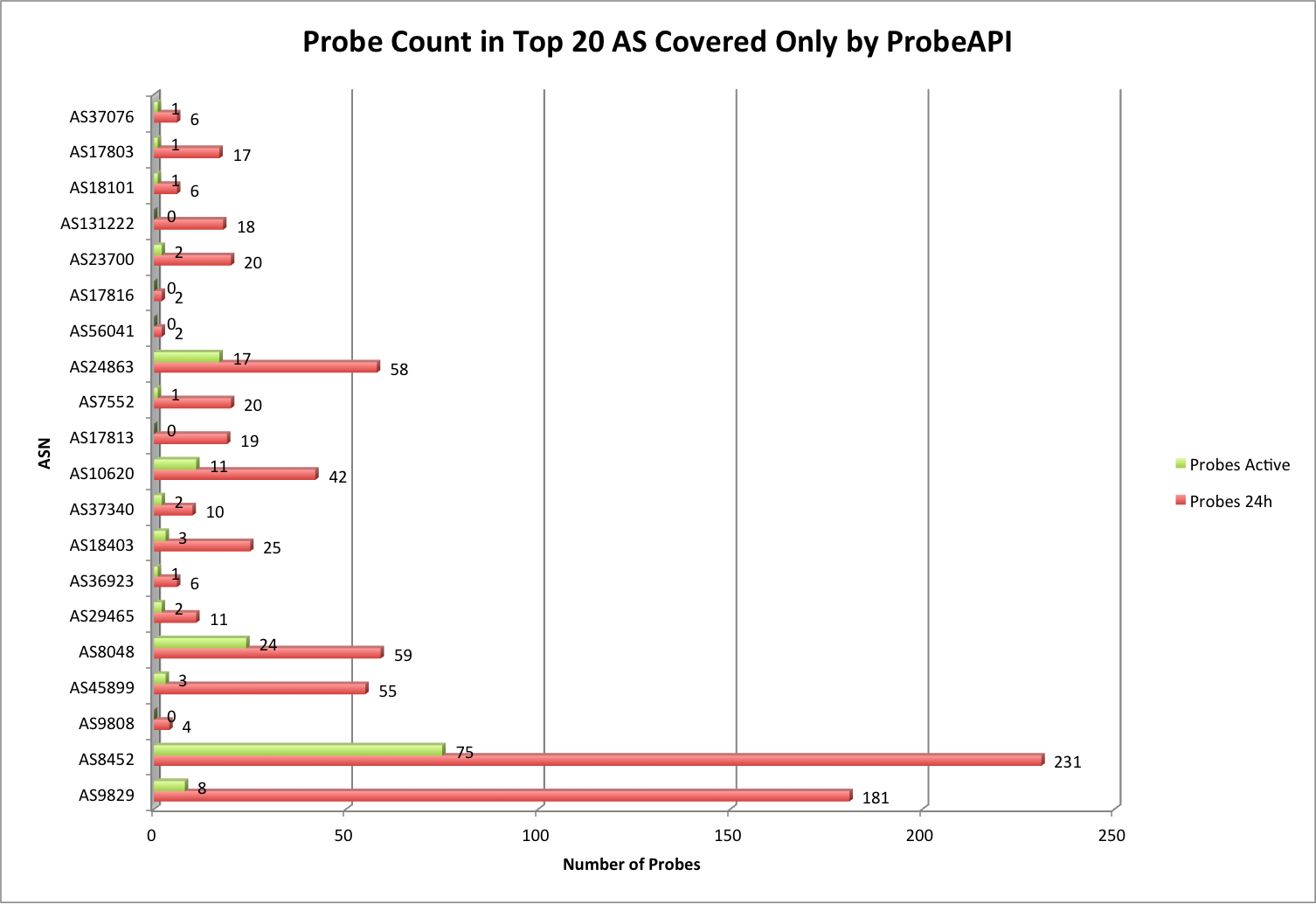
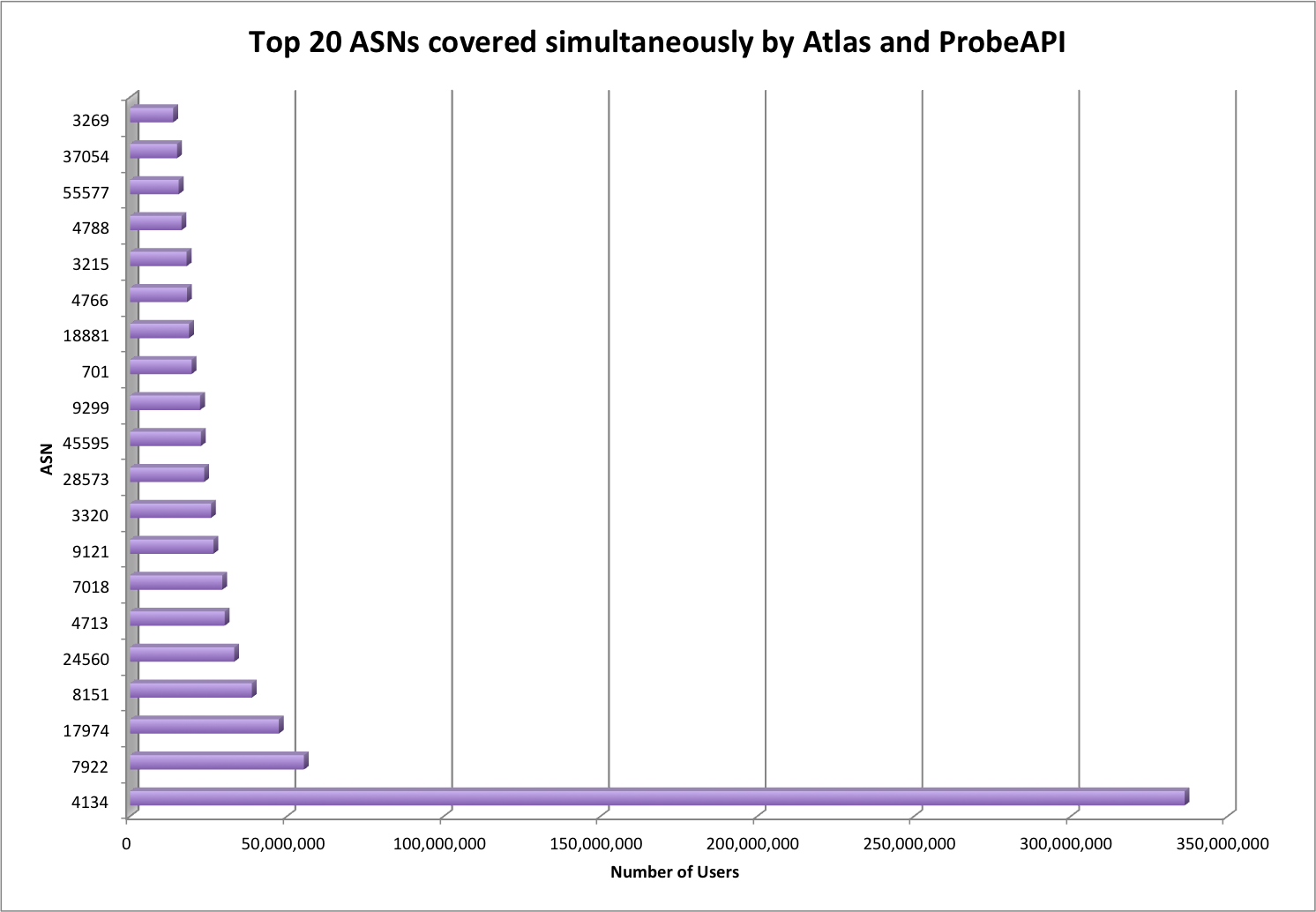
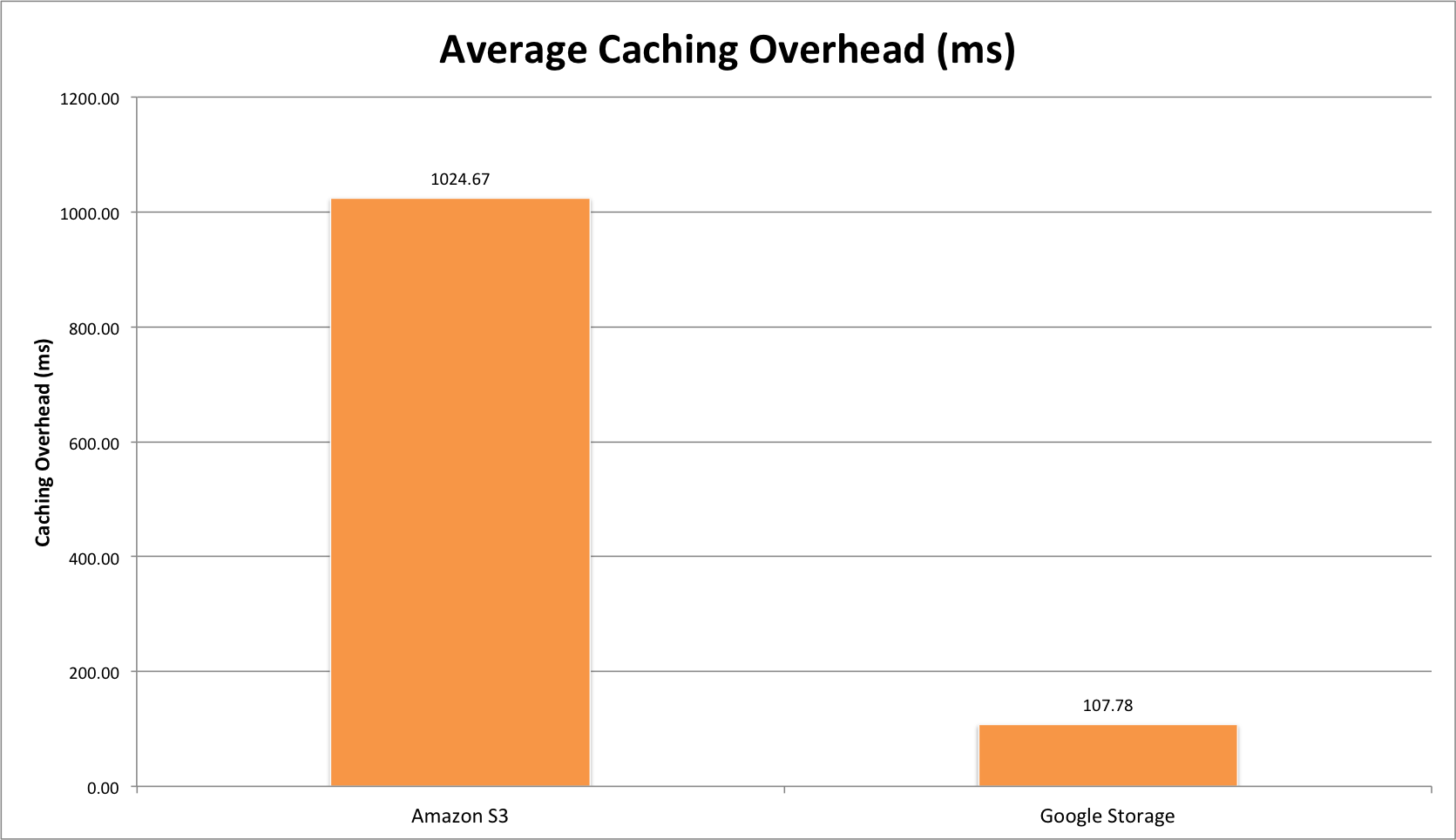
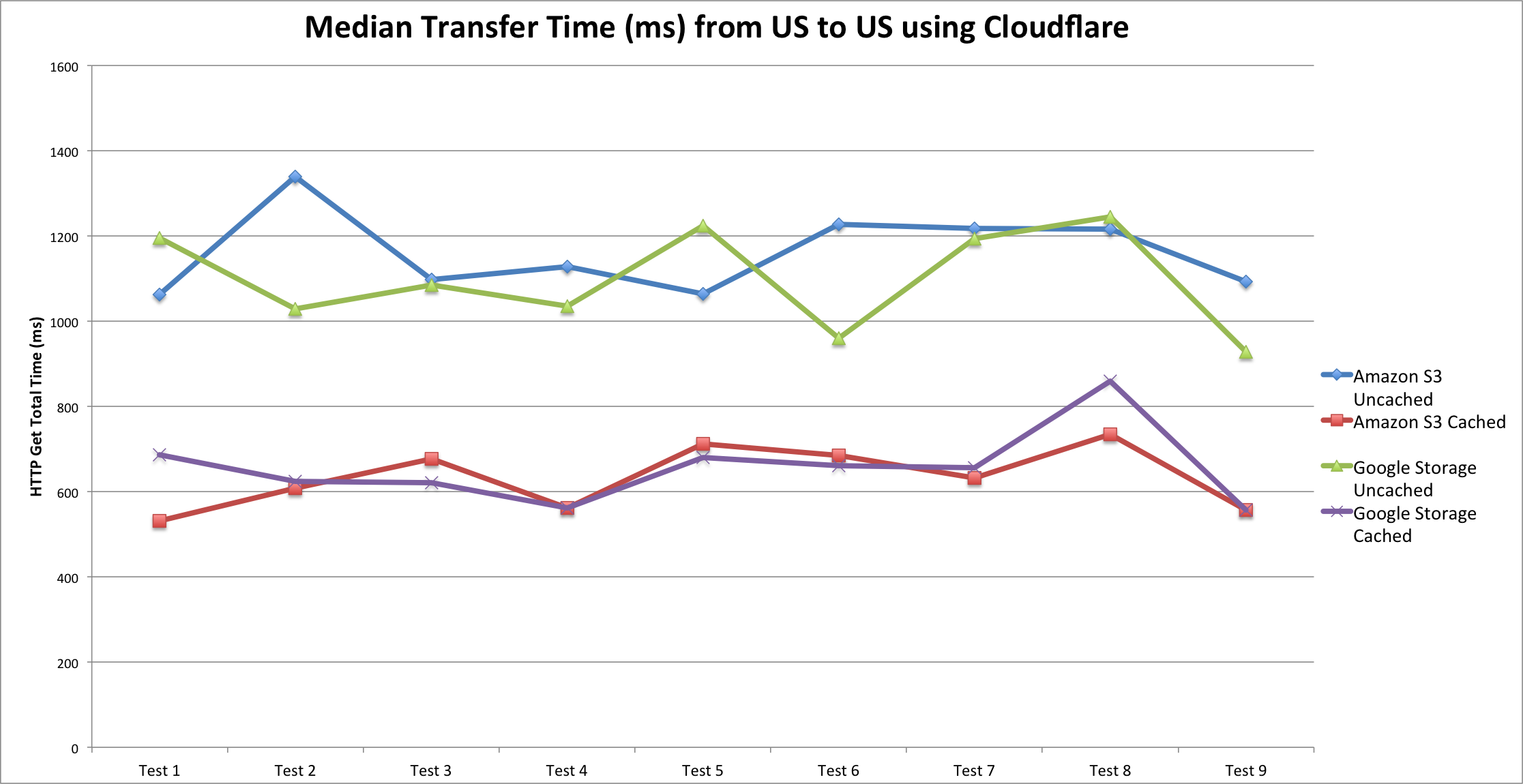
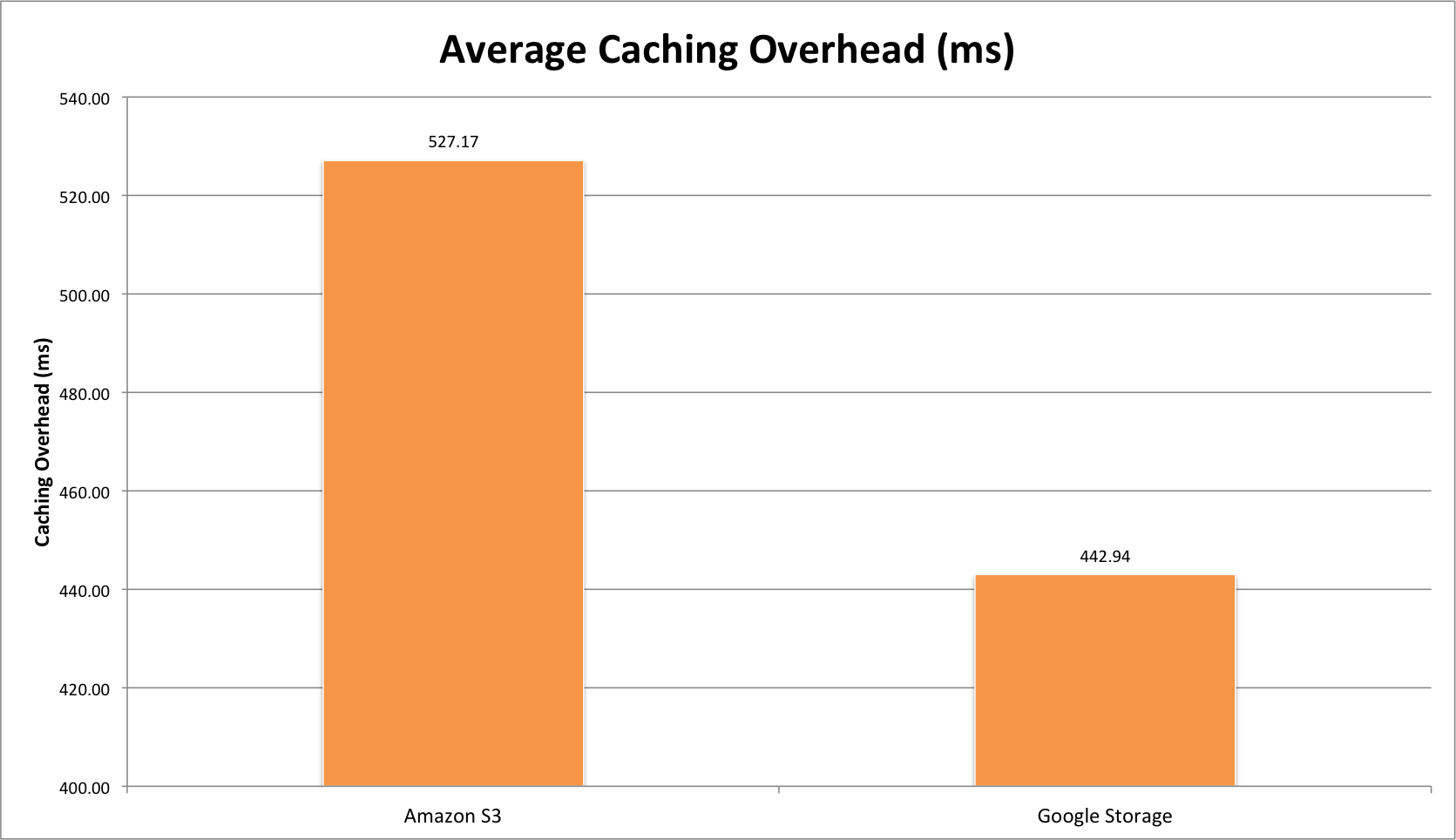
During the last years we have witnessed an explosive evolution in how the Internet is structured. Although traditional hosting and content delivery is still the norm in most cases, its basic function has been enhanced by CDNs and the advantages of cloud computing when we need to optimize our service’s presence.
On one hand, CDNs have built themselves a reputation of speed, power, “freedom”, space, air…which reflects on their market names as well: Fastly, Highwinds, CloudFlare, Skypark, Cachefly, etc. You get the idea. In many cases the technical results do reflect their marketing images, in most situations adding a CDN will probably benefit your site… but is it always like that?
On the other hand we have Cloud Computing services have improved and matured a great deal, while at the same time can offer either their own CDN connectivity or simply it’s easy to hook one up. We have found that, even without CDNs some cloud services work at CDN-like speeds and it seems that adding one won’t bring noticeable speed boosts.
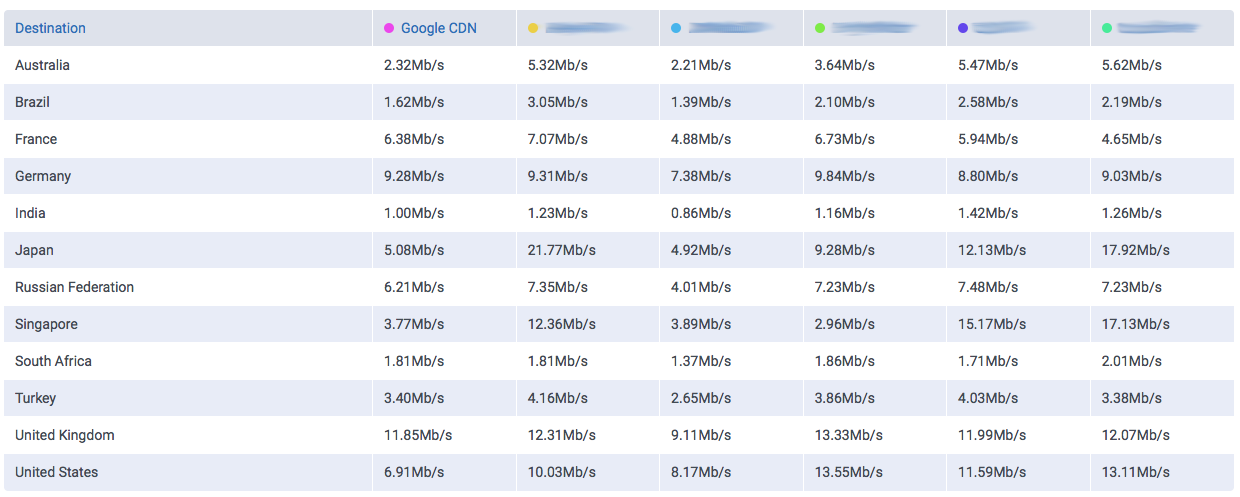
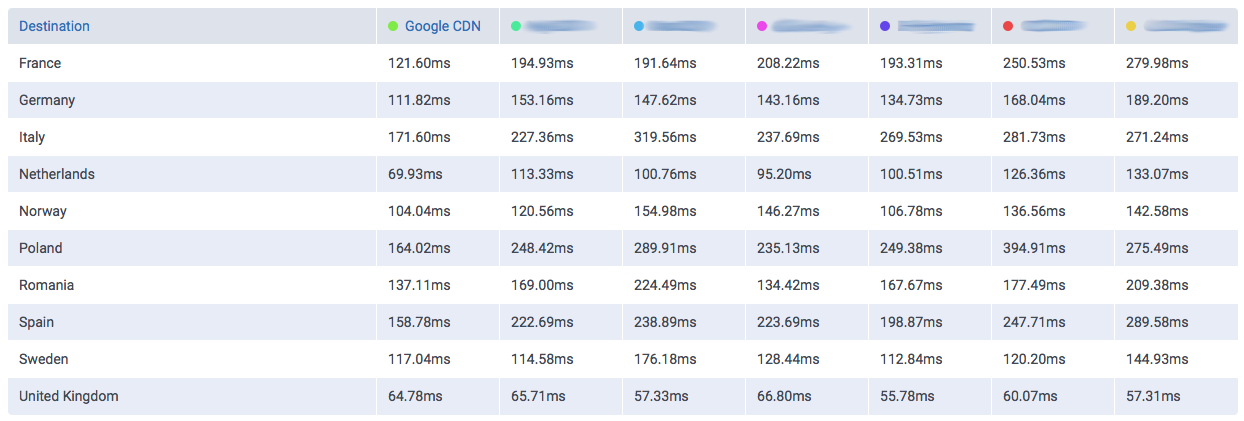
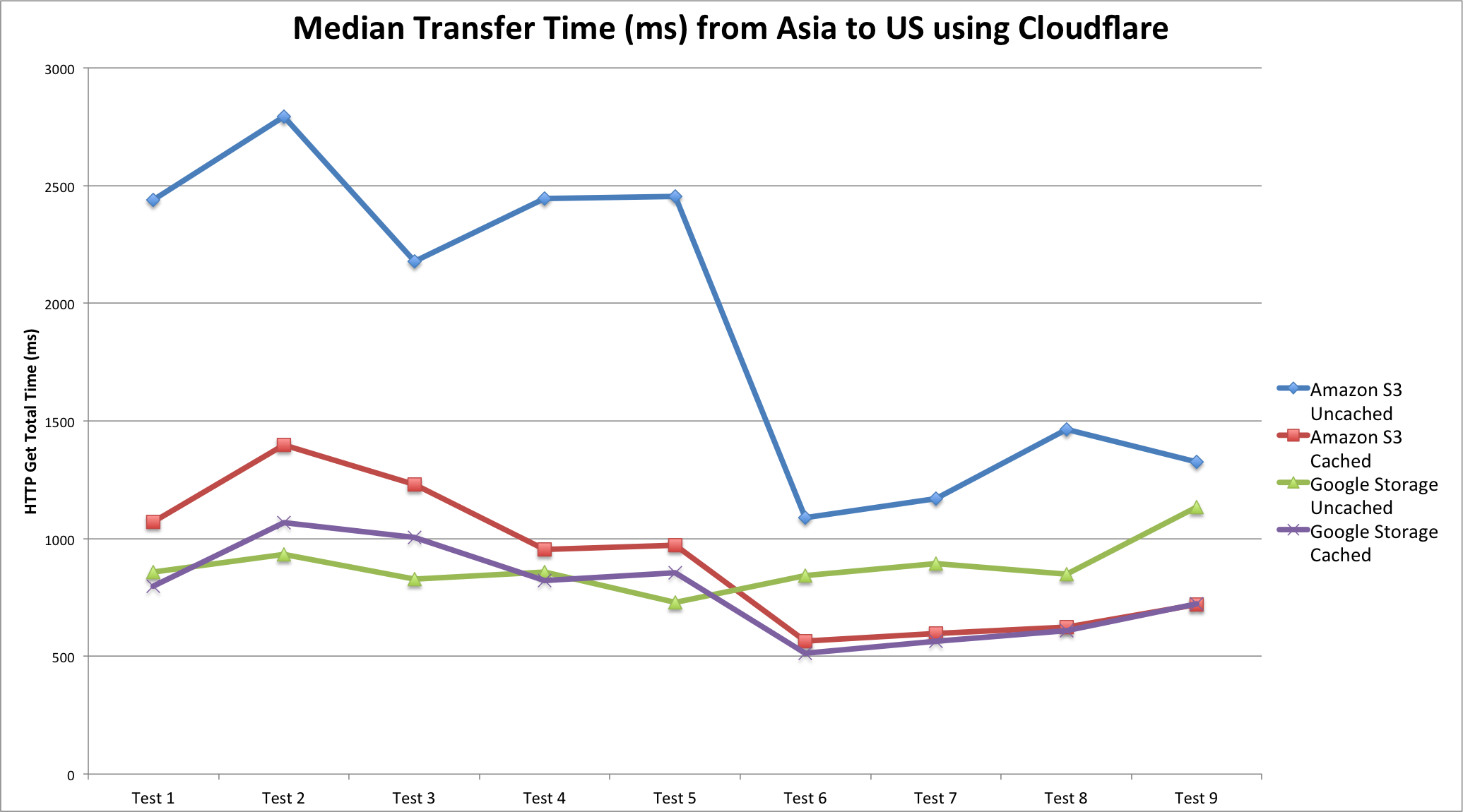
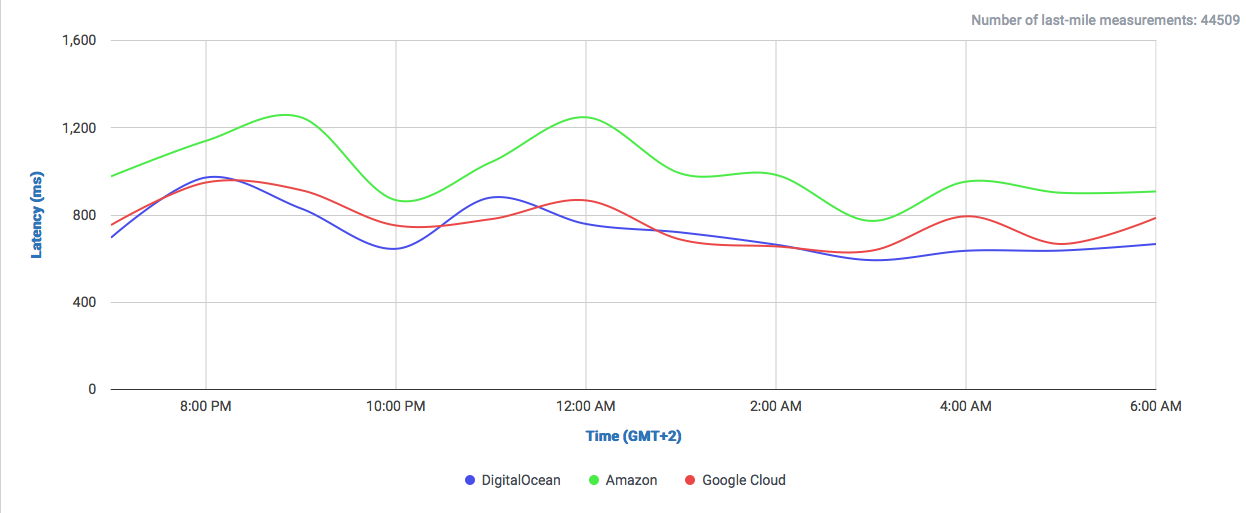
We take the case of DigitalOcean as cloud provider. Famed by their approach as a simple and clean environment and low costs, we could observe remarkable speeds in the UK using our tool CloudPerf.
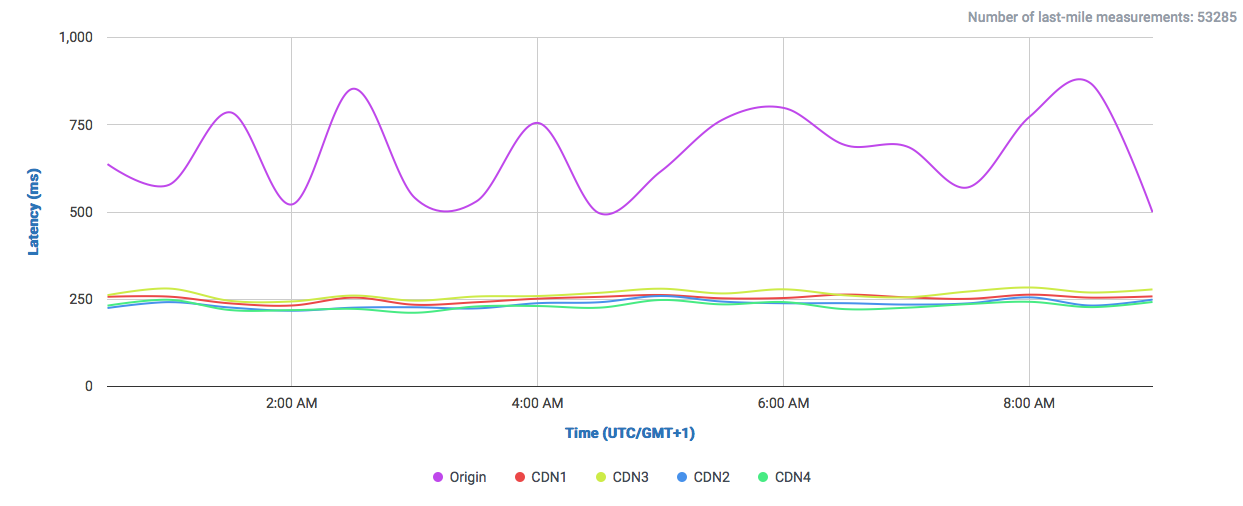
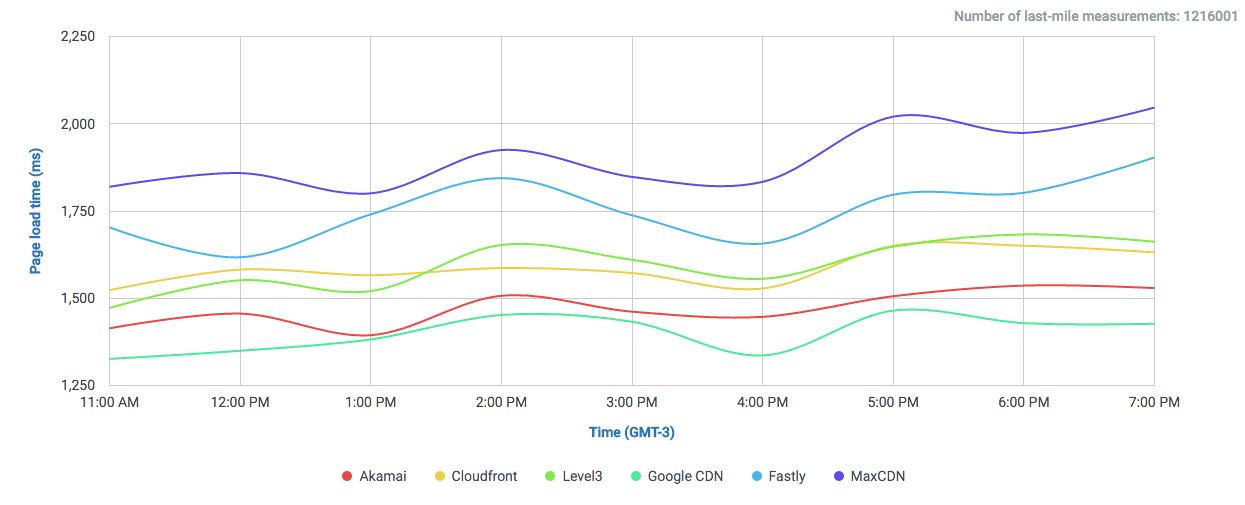
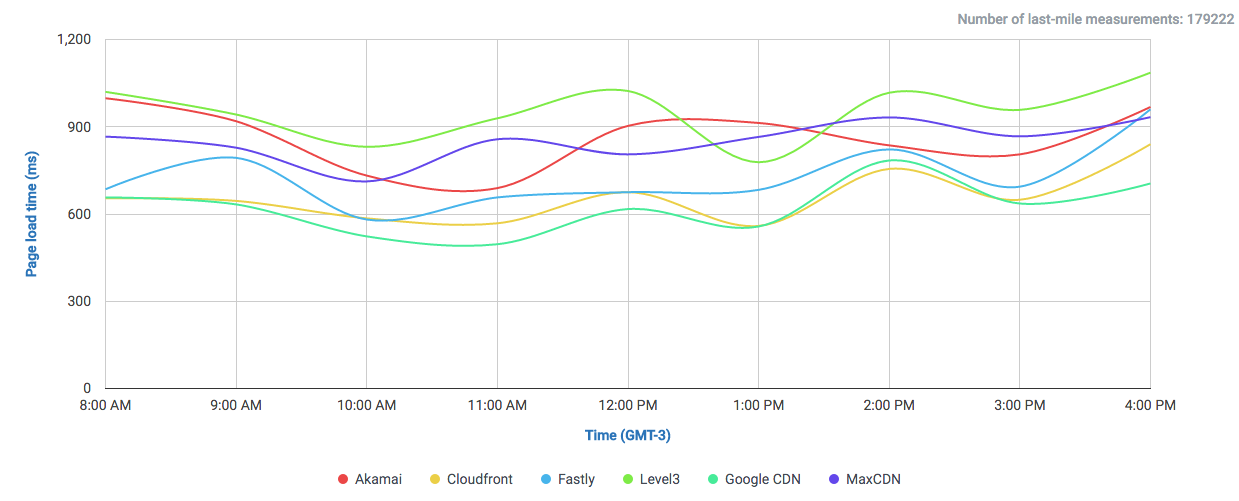
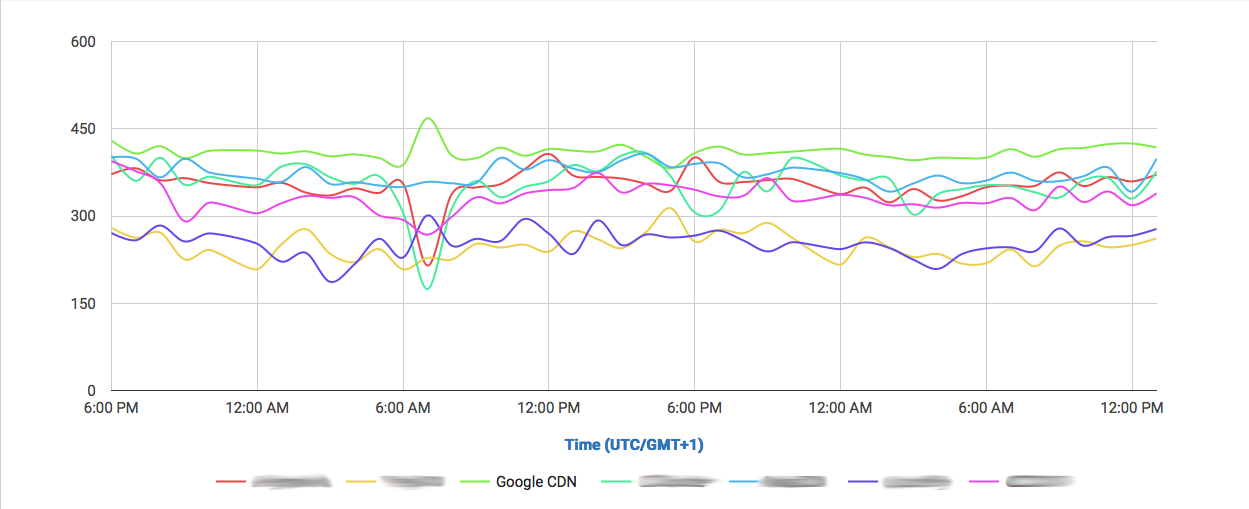
In this graph we can observe how DigitalOcean compares to Google and Amazon (without CDN) in a single 1MB object download.
We set-up a simple web-page for comparing the time it takes to load a whole page.
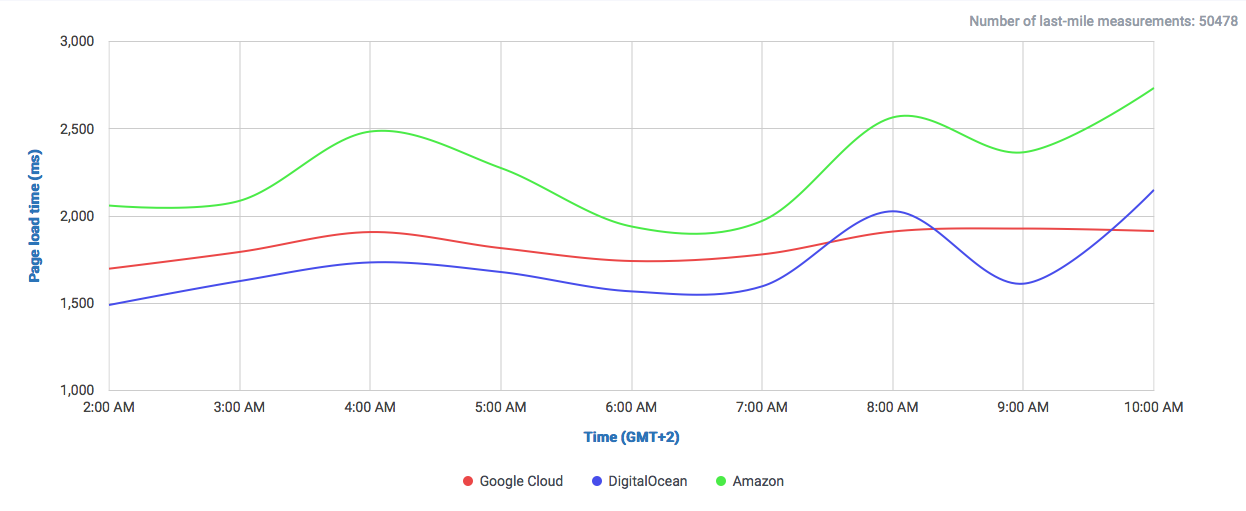
We can already observe a clear difference to both giants Google and Amazon. Both offer their own CDNs which will speed up their service, even locally. But why not get a cheaper and already fast solution?
Especially for local audiences, like this case in the UK, there could lie a very cost-effective solution for delivering low-latency content. So why isn’t this the case? One factor could be the simple, developer-oriented approach of DigitalOcean, which can be beneficial for somebody who knows how to do everything by hand, but the benefits of using a big multi-service Cloud-Provider like Google or Amazon are something you also pay for: being able to interconnect services, easy application-level management, auto-respawning of faulty machines and overall an easier management among many other interoperable options need to be taken into account… especially if you have a relatively complex machinery to operate.
You could mount a very complex network in DigitalOcean as well, but you would need to configure everything by yourself and management ends up being more tedious. In that sense, depending on your budget, sometimes paying less on one side can result in higher operational costs. Please take into account that we are actually comparing a VPS solution against complete Cloud service providers.
On the other side, DigitalOcean is an example of how the Cloud is becoming more and more affordable, to the point where it competes against traditional web-hosting prices and still delivers high performance. You can literally have a new server up and running in less than a minute and maybe 5 minutes if you’re new to it. Since there isn’t much to fiddle around, this very straightforward and simple approach will spawn you one or more new servers instantly, with public ip-addresses and pre-installed keys to log in remotely by ssh. Starting from $5 a month for a basic VM running on the Cloud.
Even if you already use another Cloud provider to run your machines, trying this out won’t hurt at all. Hooking up a CDN to it is very simple and even IF you need it. Since the high performance of the service itself is already on-par with CDNs, you can think it twice if it’s truly beneficial to use one.
This is a point we would like to stress: a CDN by itself may or may not accelerate a service. The decision of which CDN to use and whether it fits your own user distribution is a complex question which requires a well researched individual answer for each case. Having stated that CDN isn’t synonyms with “higher speed”, we woud like to ask again: why isn’t this option more popular? Maybe is it the already established usage of a Cloud platform, which makes it convenient to just spawn a machine and control everything from the same place. Maybe adopting another provider is too much extra papework, or maybe the public simply isn’t aware of this.
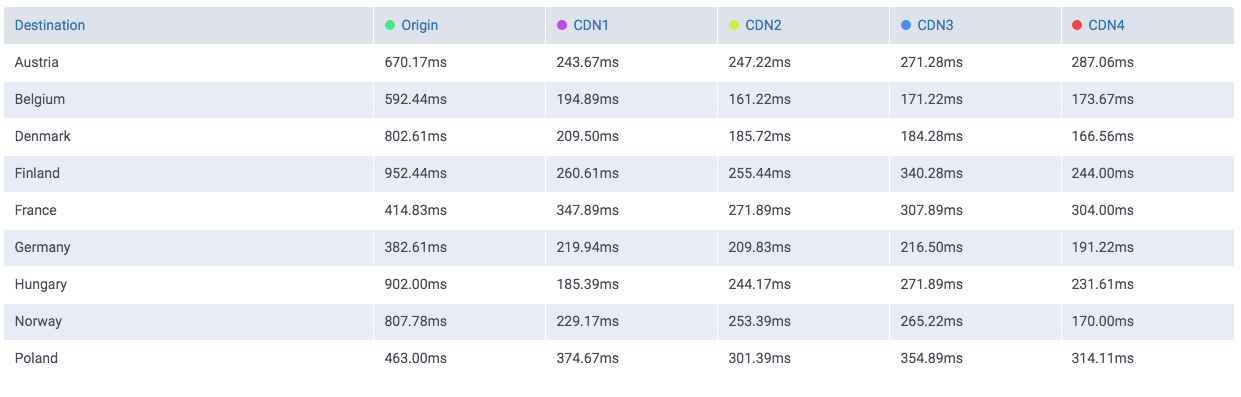
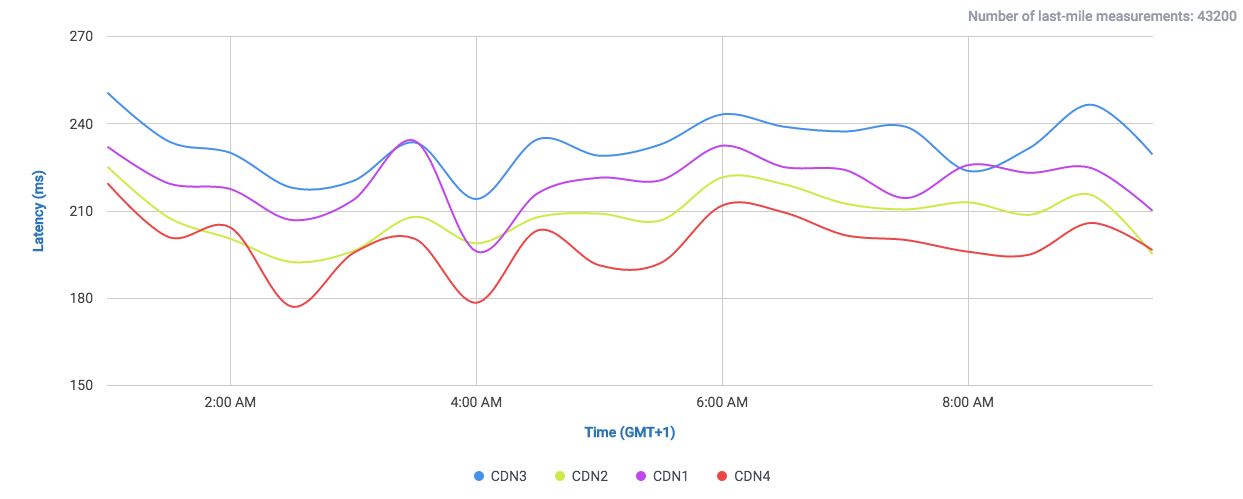
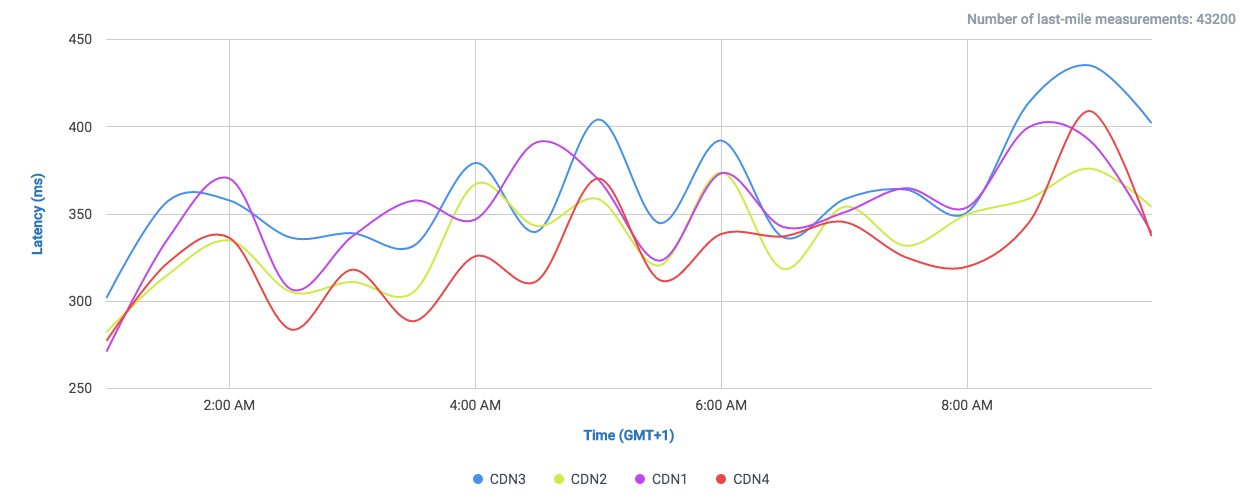
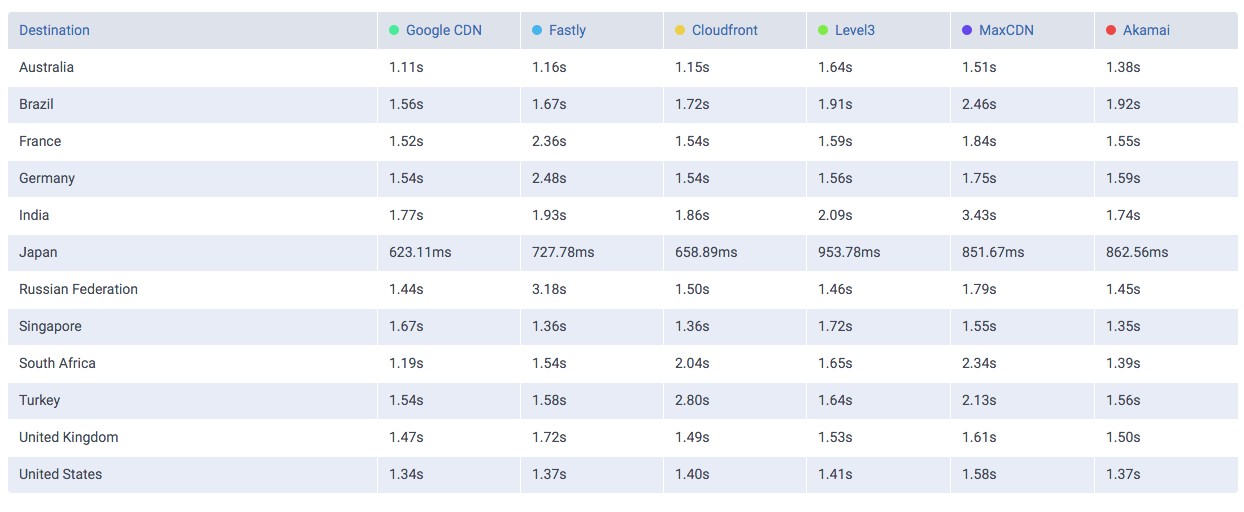
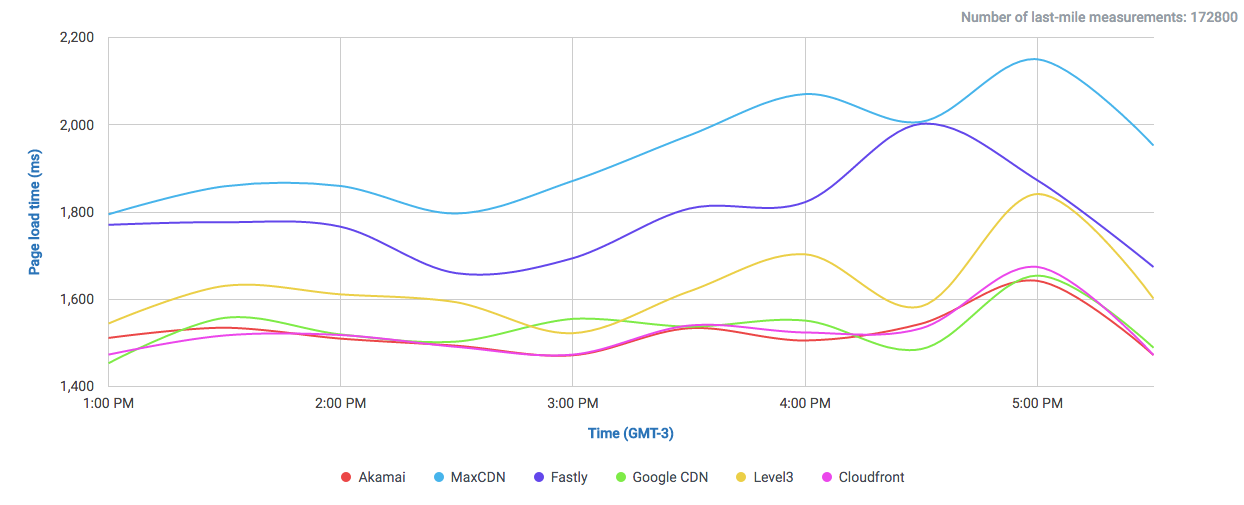
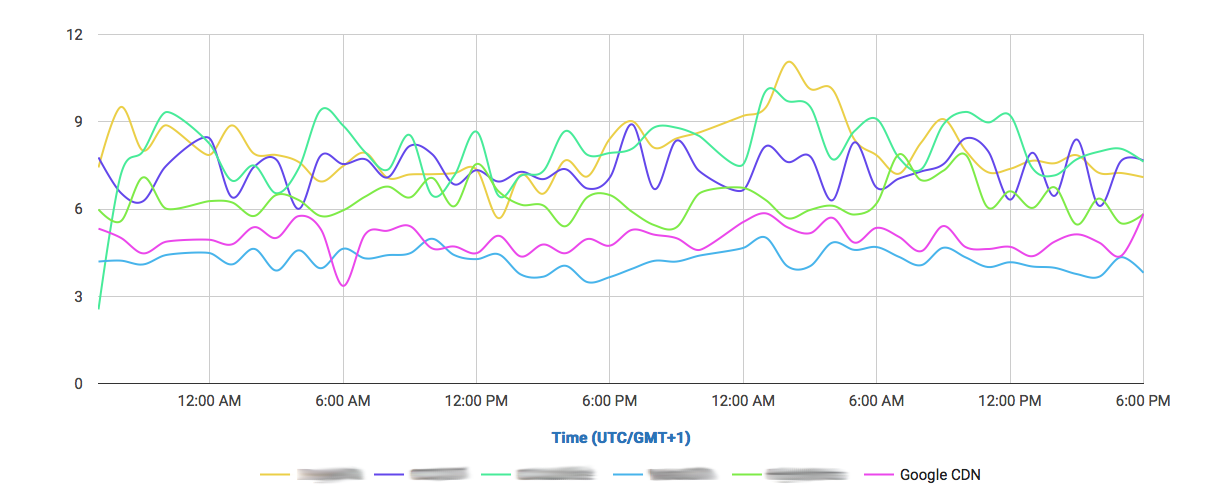
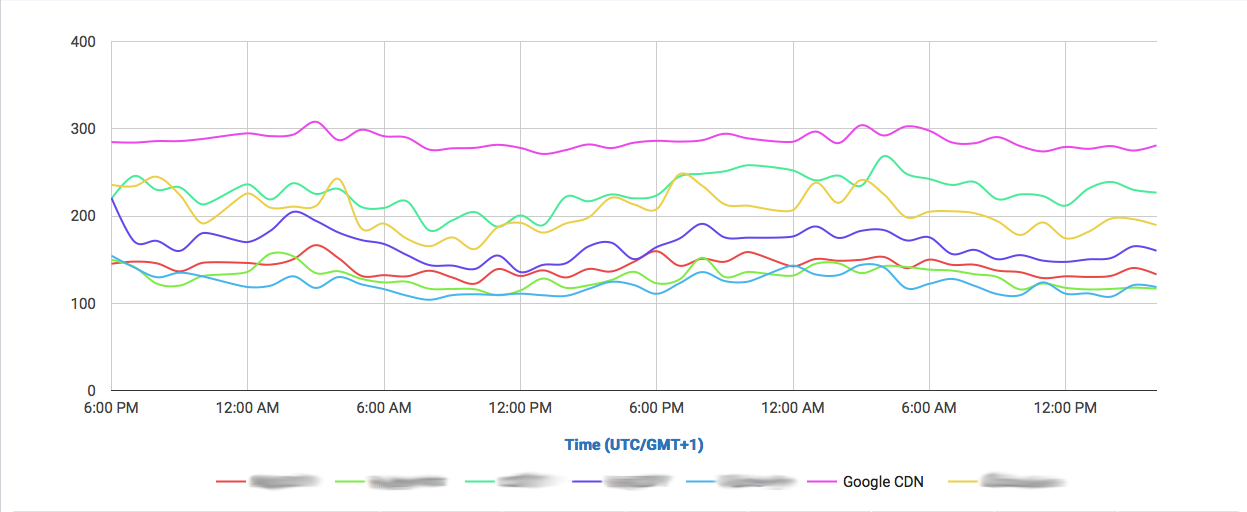
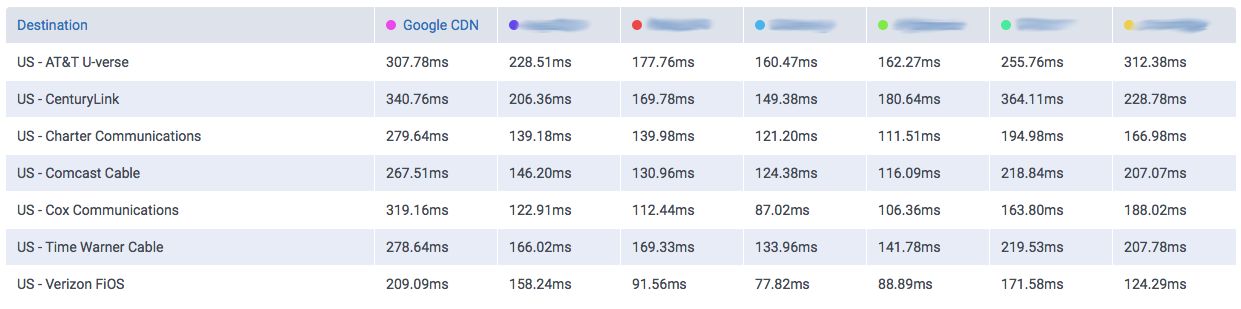
Let’s take a look at the following comparisons, where CloudPerf measured DigitalOcean against multiple CDNs in the UK:
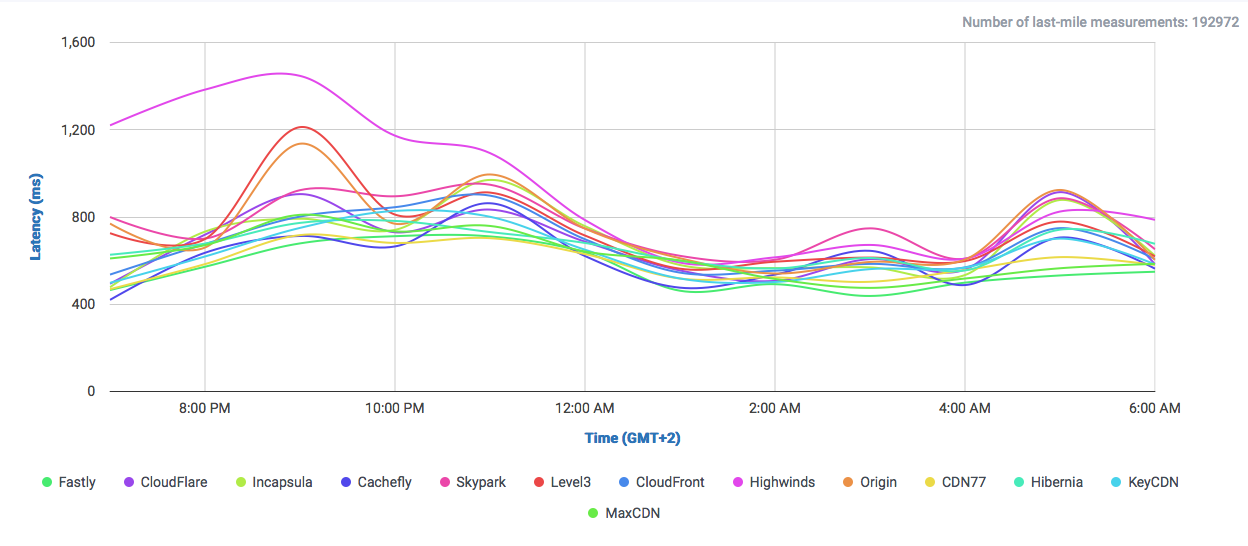
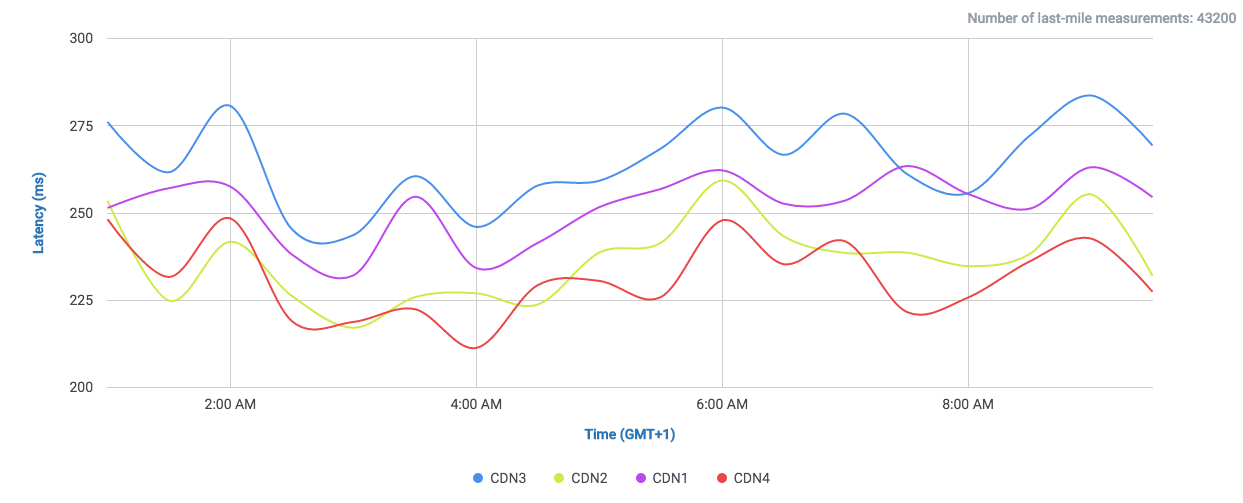
If we compare DigitalOcean’s (here labeled as “Origin”) performance in the UK directly against CDNs we will find that it is at least on-par with most of them.
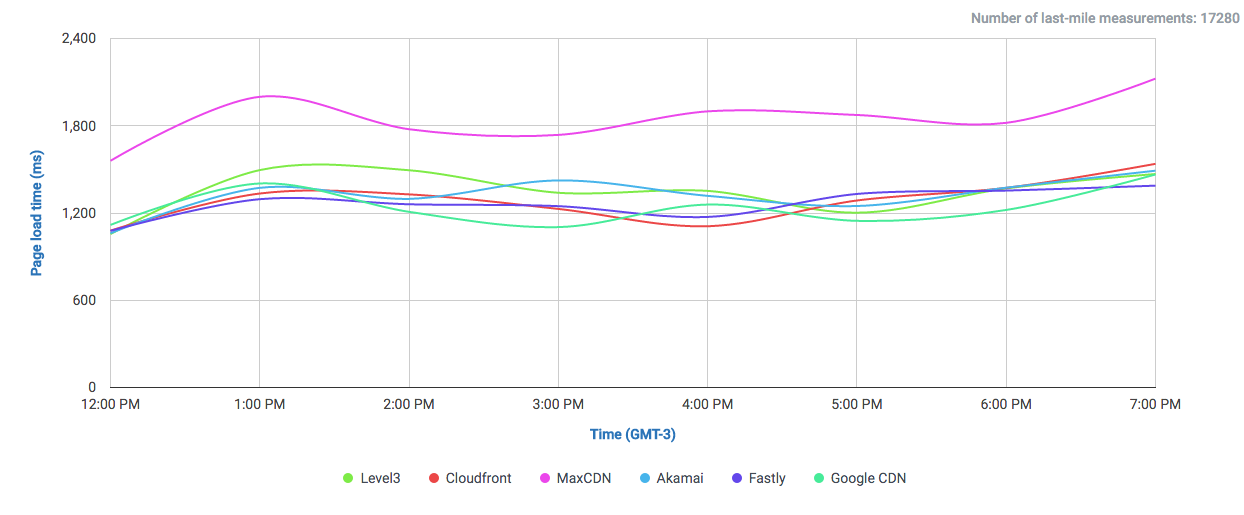
And if we filter out most of them and take a look to the CDNs performing the closest:
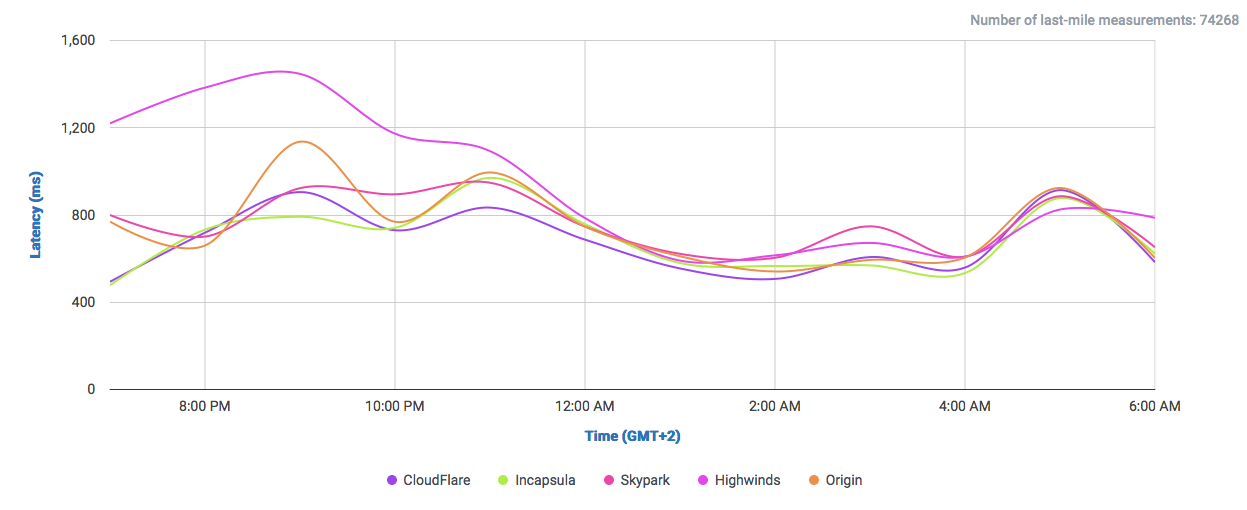
We find that it performs even better than Highwinds and Skypark. With CloudFlare and CloudFront performing with better averages.
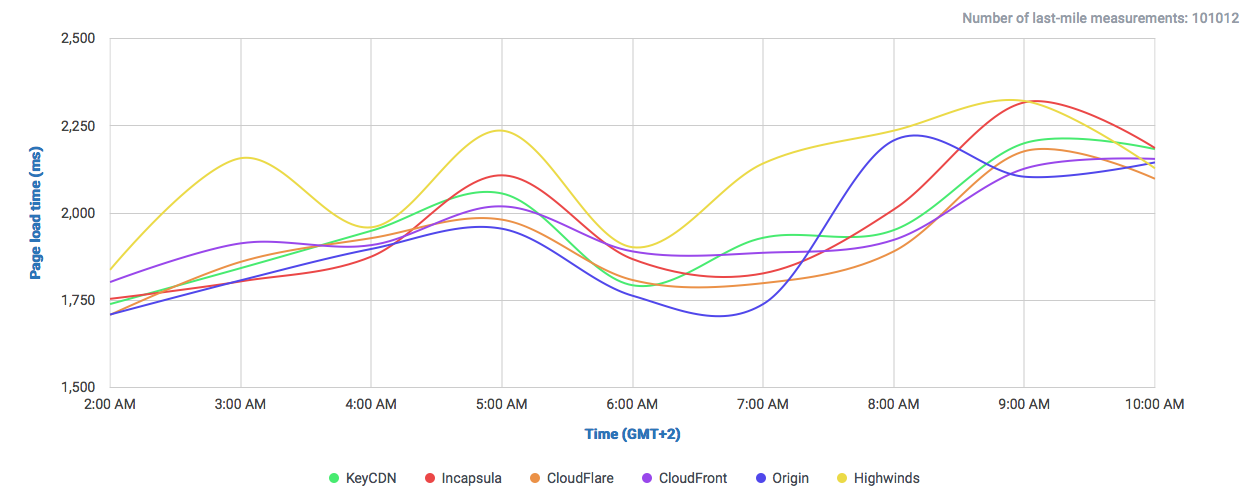
So, looking at the example we showed here, if you have your audience near any DigitalOcean location, then you’re probably not going to need a CDN to speed up you service. Nevertheless, depending on what solution you adopt, you could benefit from other features of CDNs, like added SSL security and easy escalability without having to resize machines in many cases.
When we compare prices, the picture gets even more interesting. Let’s take DigitalOcean’s $20/month package: you get 3TB of data transfer included and a generous VM. That’s $0.03 per hour and $0.0067 per GB together in one price. A similar configuration in GCP will cost approx. $28.08 only for having the VM and ~$460.8 for 3 TB of traffic, that makes ~$488,88 a month. In AWS a similar config would cost ca. ~$40.32 for the VM and ~$476.16 for 3 TB of traffic, that’s ~$516.48. So DigitalOcean with $20 a month will give you an equivalent of ~$500 investment in other platforms.
What about the bigger VMs? The biggest plan DigitalOcean offers is $640 a month for a very capable machine and 9TB data transfer included. An similar setup in GCP will cost ~$449.28 ($0.624/hr) plus $1024 for 9TB of traffic giving a total of $1473.28. In AWS you can either choose a $0.528/hr which is a less capable machine but similar in price or $1.056/hr for a more similar one to the ones used in the competition. 9TB of data transfer will cost $1428.48 and running the VMs will cost either $380.16/month or $760.32/month, giving a total of ~$1808.64 for the smaller machine or ~$2188.8 for the bigger one. In any case expect to pay around $2000 a month. All that without CDN. To make things simpler, if we assume an approximate price of $0.1 per GB in a CDN, we find that you have to put $300 or $900 on top of your already existing hosting costs for accelerating those 3TB or 9TB of data respectively.
Please take into account that these figures are an approximate calculation since, as you may very well know, pricing in Cloud services and CDNs is extremely dependant on what resources, how and when were they used. In that sense, this also favours DigitalOcean in giving you a clear and straightforward fixed pricing structure.
Summing up, we have seen that a simple Cloud VPS provider like DigitalOcean can achieve very low latencies locally in the UK. We compared its performance and pricing against Google Cloud and Amazon S3. We saw that DigitalOcean generally performs better than both. Then, comparing DigitalOcean’s performance against CDNs serving the same content, CloudPerf reported that the VPS by itself is fast enough in the UK to compete head to head against CDNs. In this perspective, we can only recommend to analyse and think twice what kind of solution you need to adopt. For that matter, making an informed decision without measurements sounds indeed contradictory. Using our tool CloudPerf, we discovered particular circumstances where a large very important location like the UK can be covered simply using a modern high-performance Cloud VPS service.
Do you want to discover your best options yourself using CloudPerf? Sign up now!