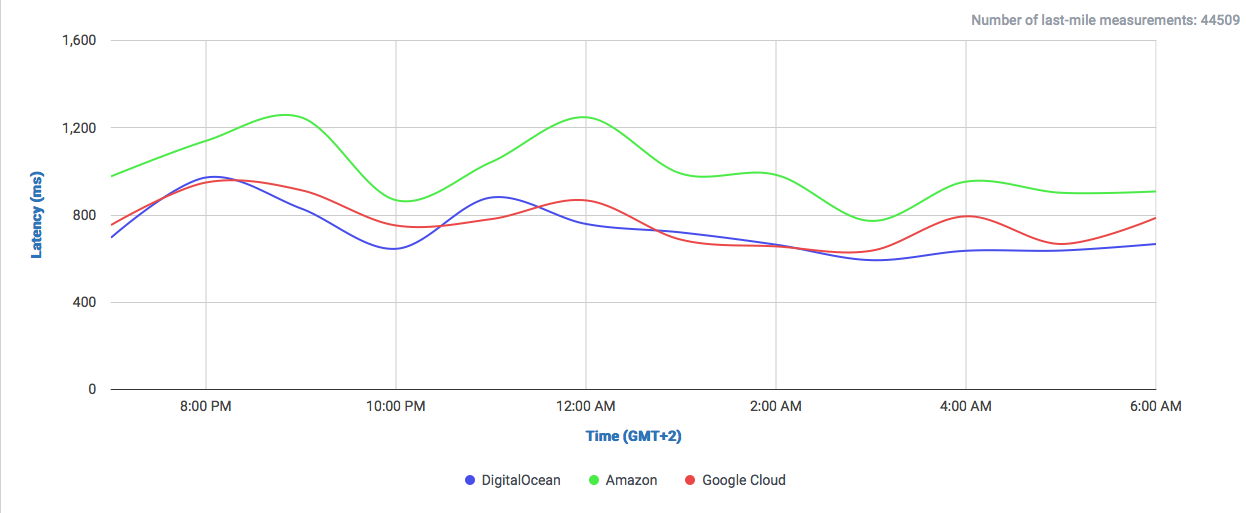
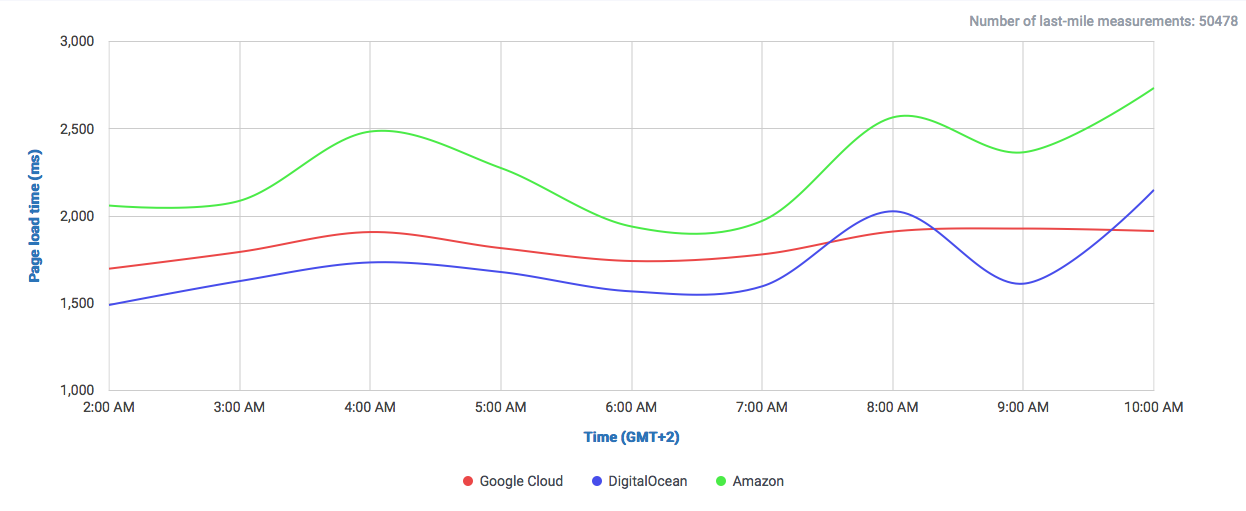
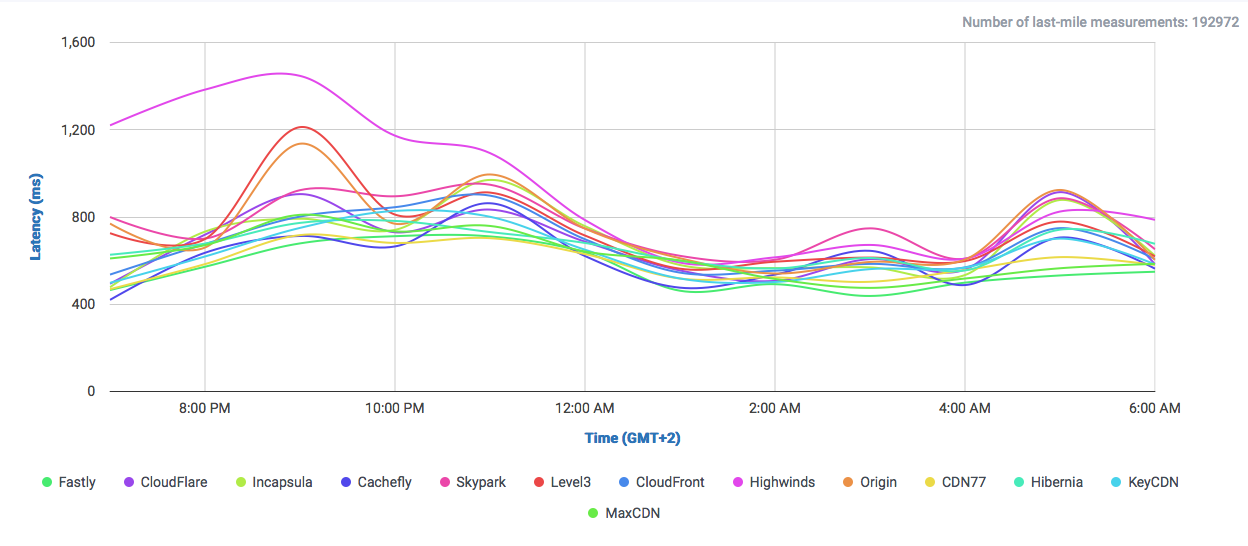
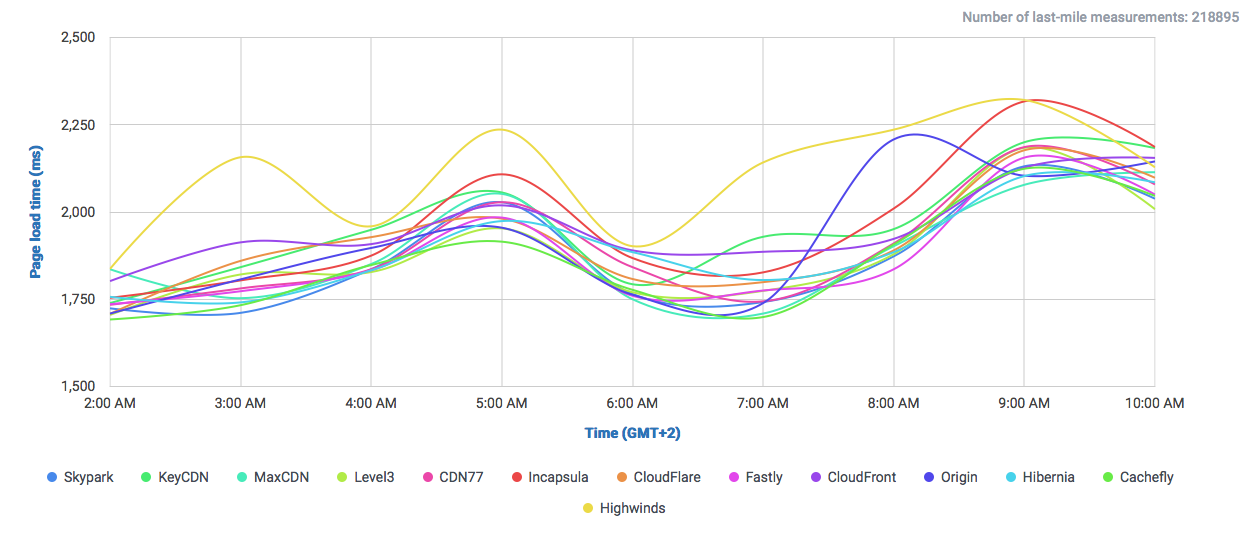
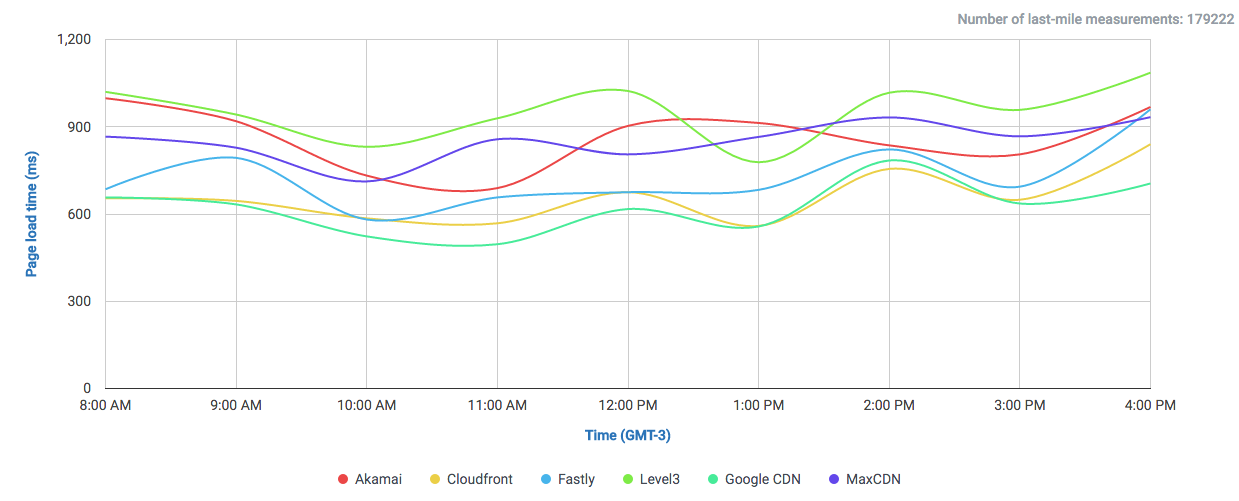
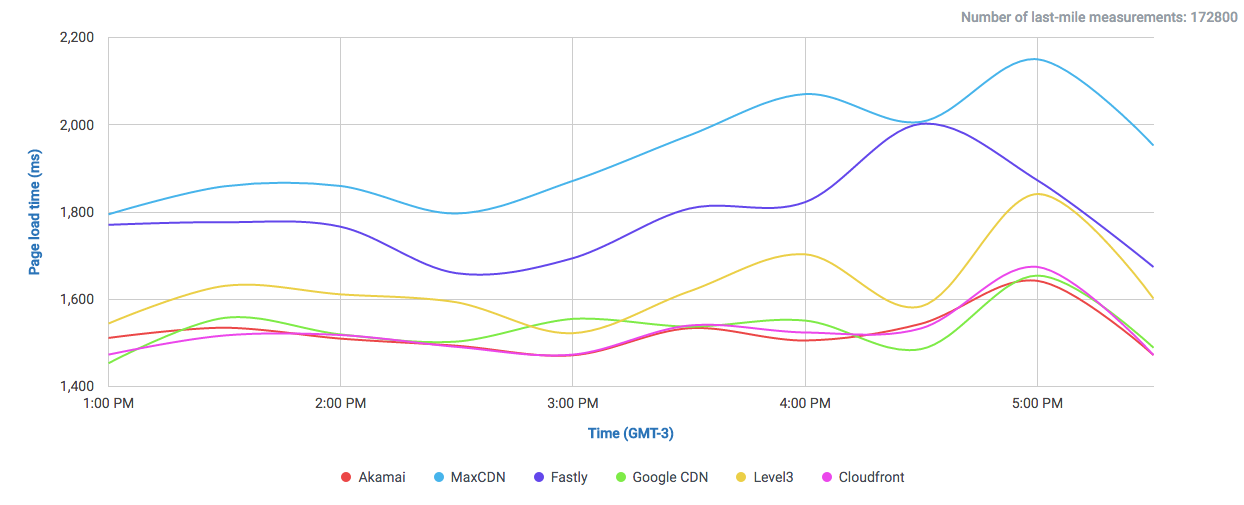
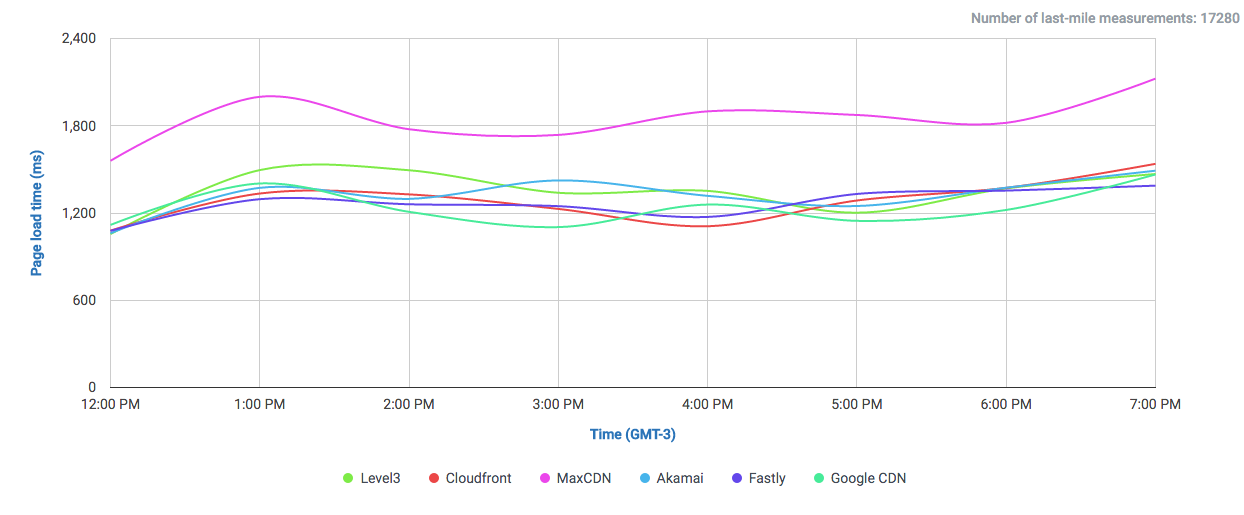
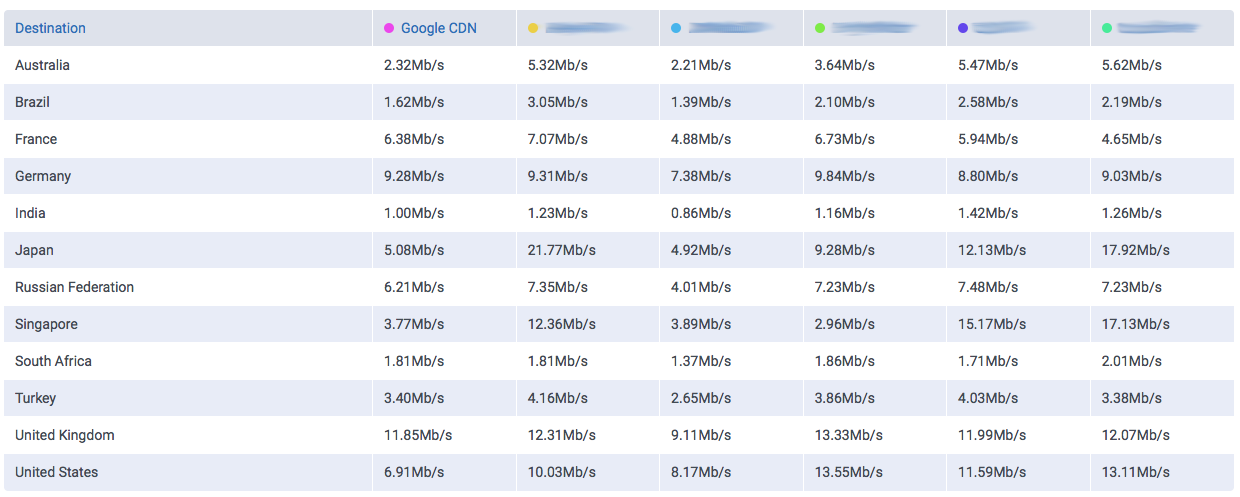
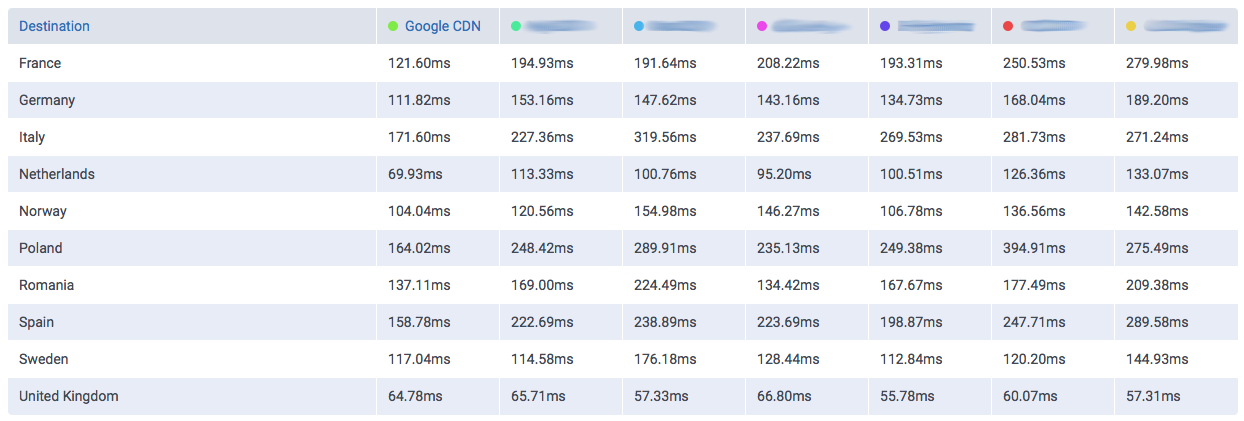
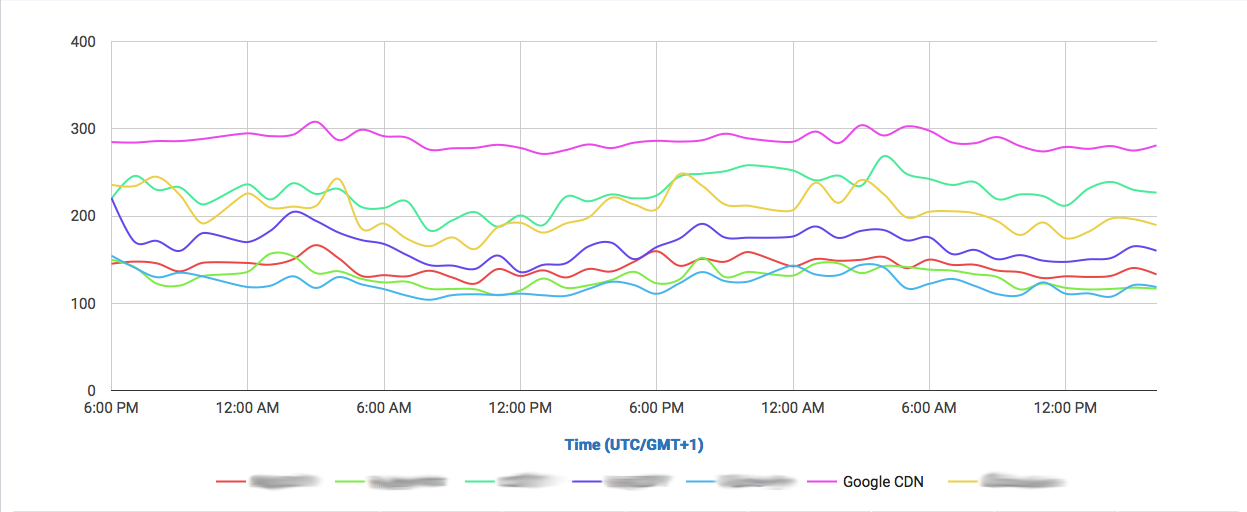
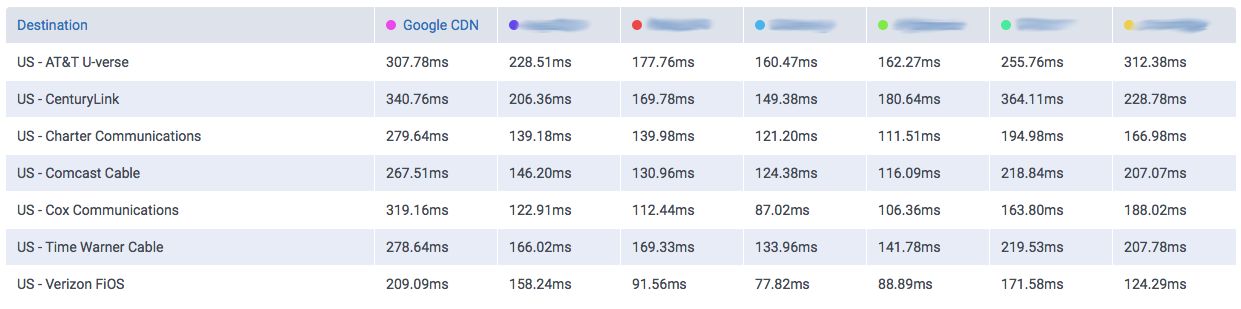
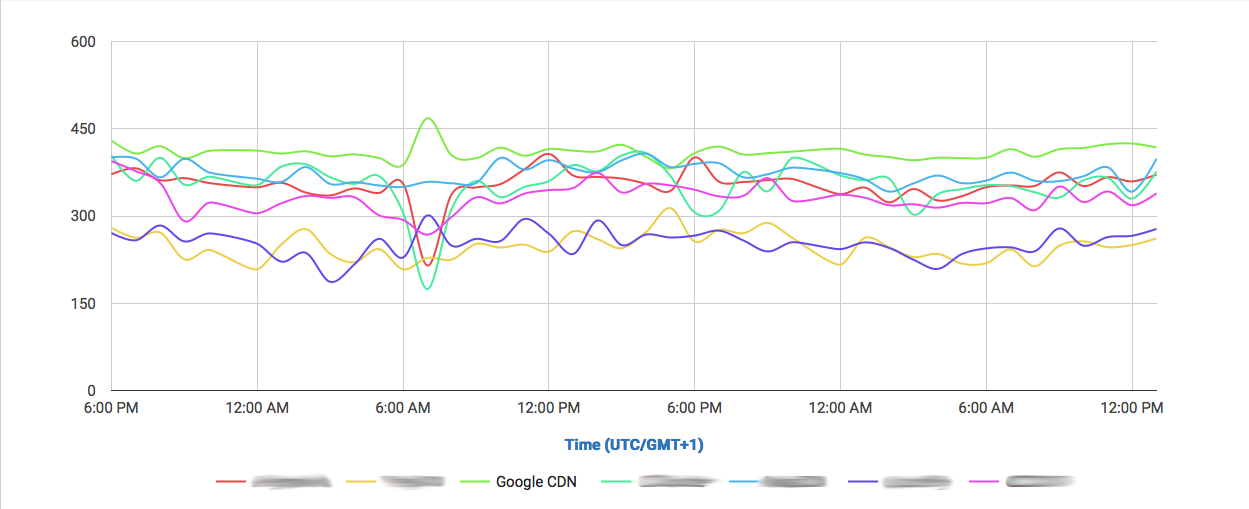
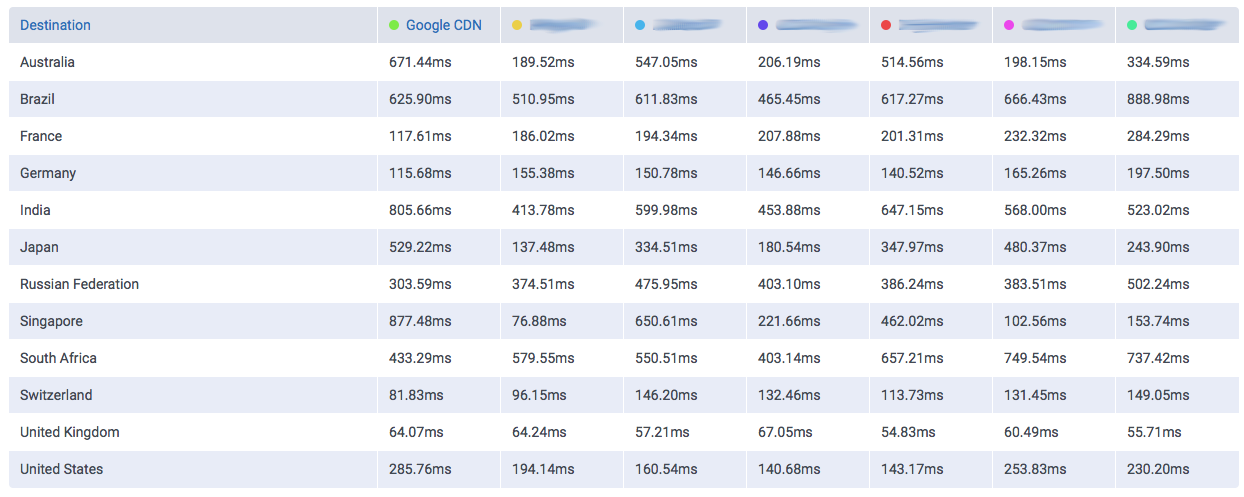
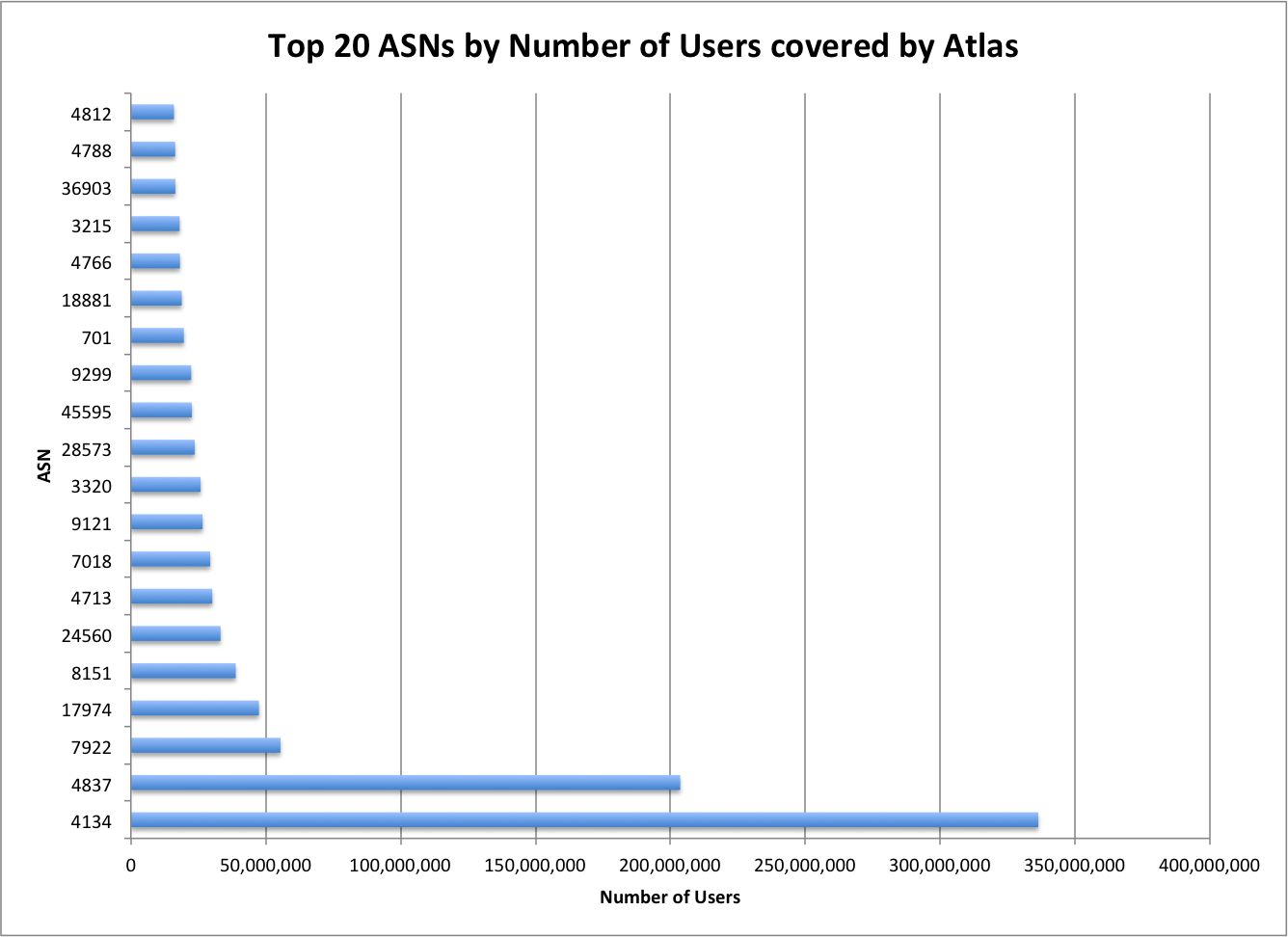
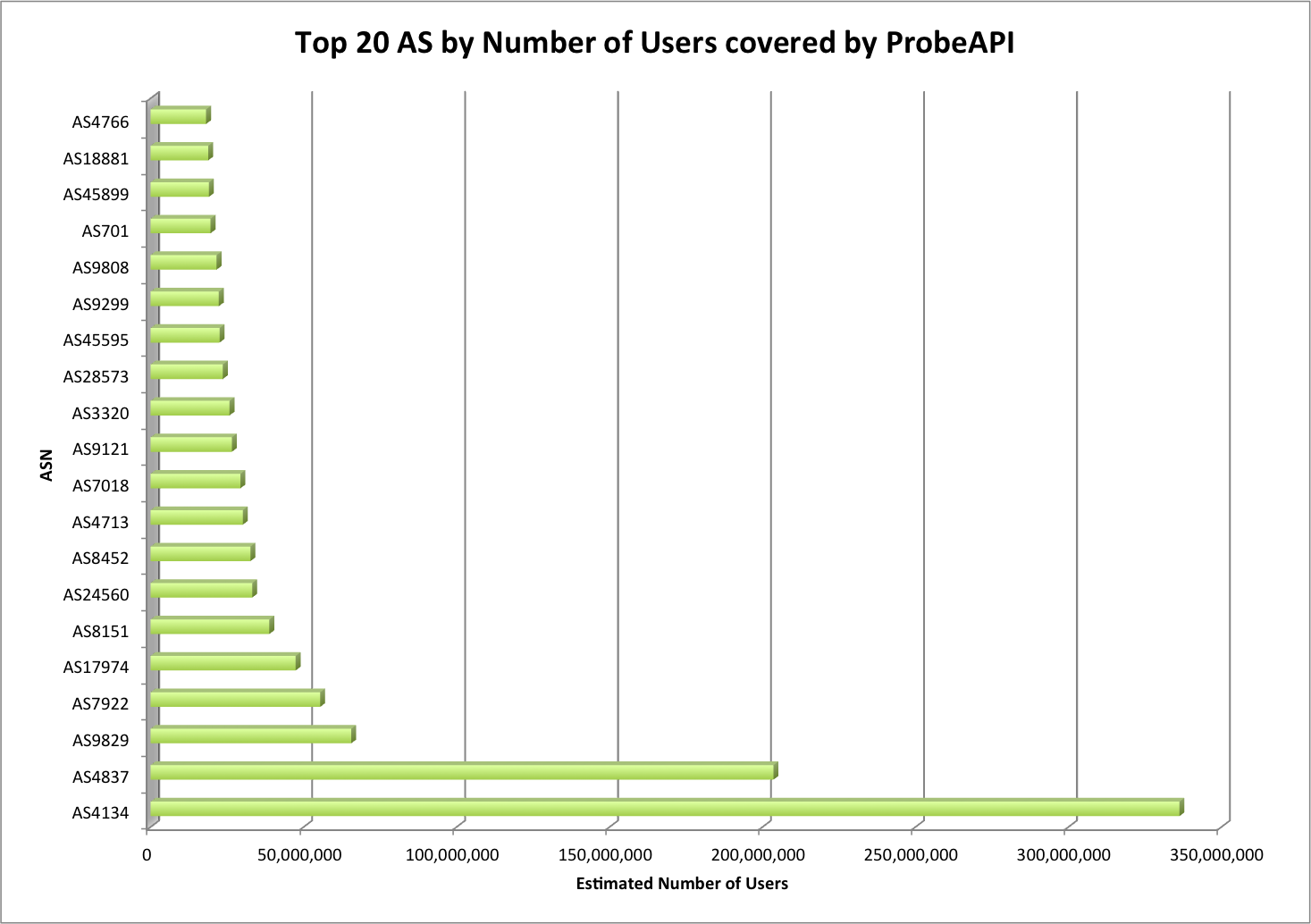
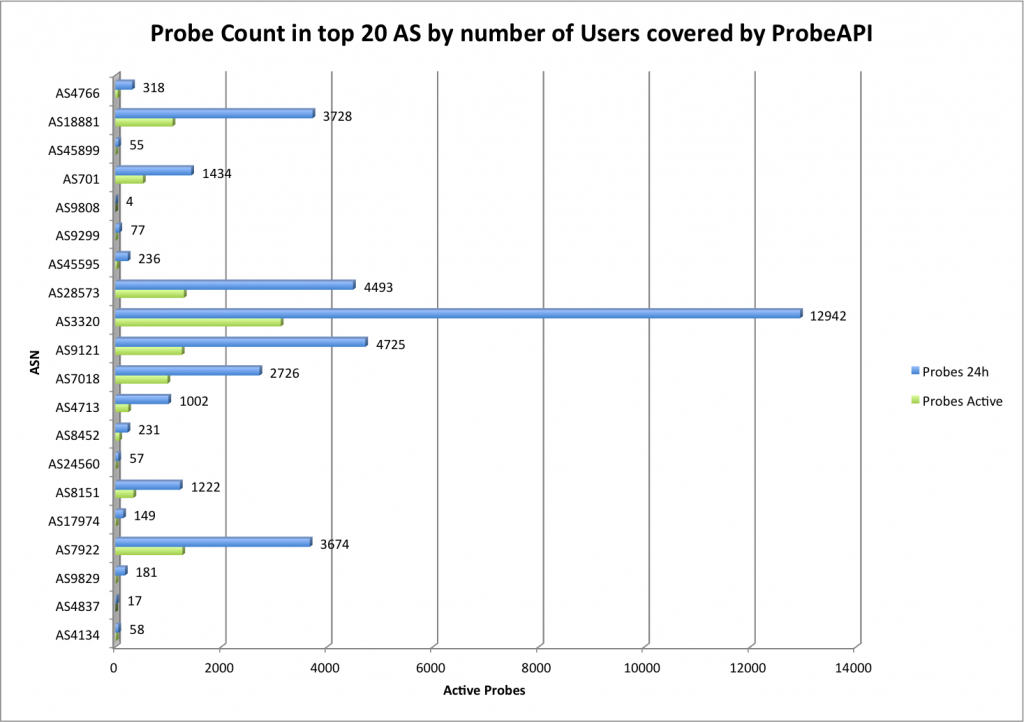
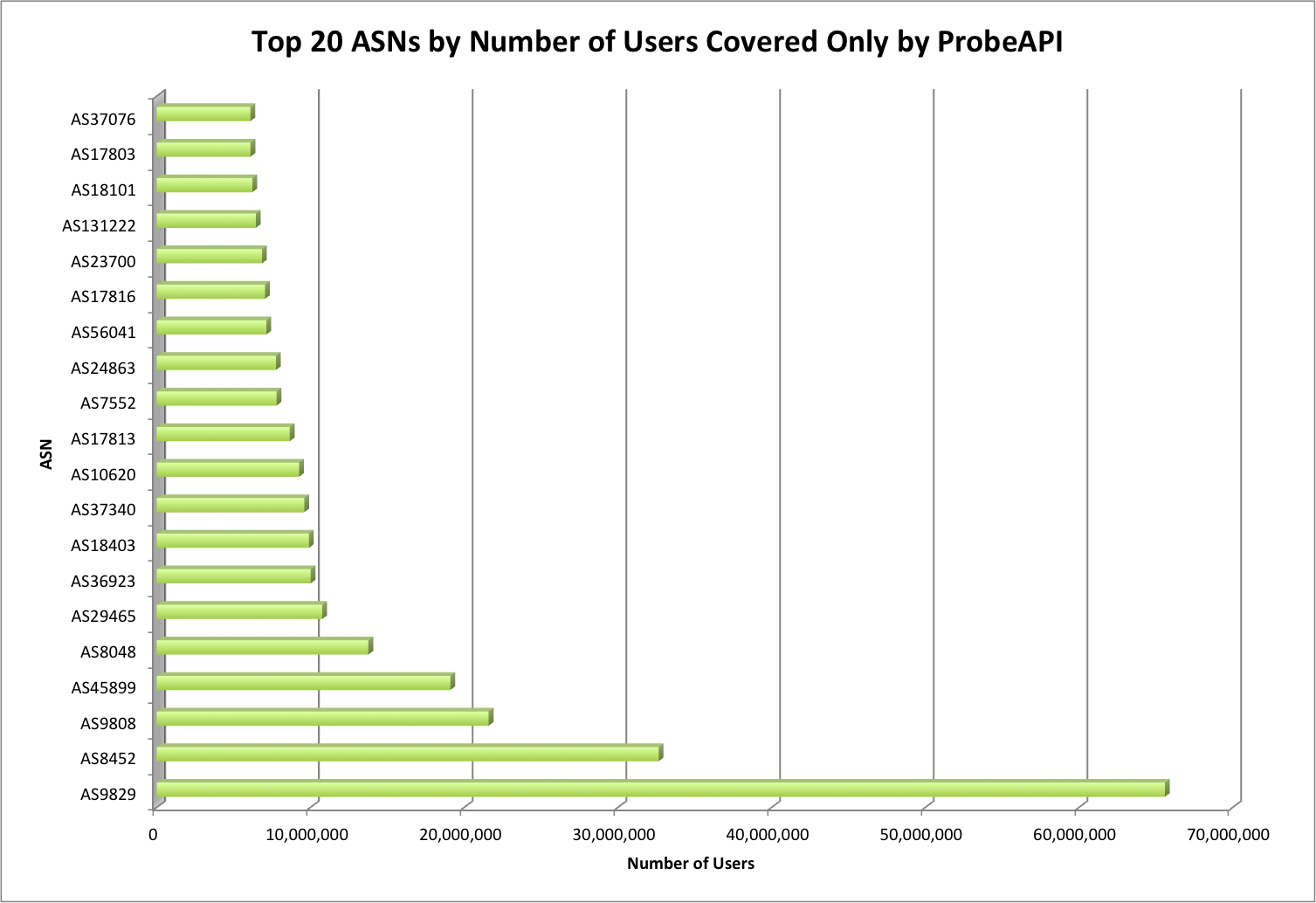
The amount of data Google serves through the Internet is undoubtedly enormous and their network is correspondingly efficient in doing so. One key component of Google’s information superhighway is their CDN-Like Cache infrastructure: the Google Global Cache. We ran some tests with ProbeAPI and had a closer look at this vast network, which enables us to enjoy Youtube at the best quality our ISP’s capacities allow.
Our experiment showed us the extent of the deployed network in its worldwide coverage. We were able to observe the impressive number of 2383 Cache Instances across 800 locations all around the globe. It is important to take into account, that there may be more locations where a particular ISP wasn’t available through any probe when we ran the experiment or, for example, we have no probes in an ISP which runs through a particular Cache Server, especially in remote locations where the presence of ProbeAPI Probes is still scarce.
We used all the available probes at the moment we ran the experiment, delivering a total of 240184 individual results, which were grouped and cross-linked to obtain relevant data.
The cache locations are codenamed with three letter airport-codes. Cross-linking the Airport codes from the IATA with the codes obtained from the Cache-Servers’ names, we were able to obtain their approximate geographical location.
|
Continent
|
Detected Cache Instances
|
|
Asia
|
740
|
|
Europe
|
620
|
|
North America
|
487
|
|
South America
|
347
|
|
Africa
|
103
|
|
Oceania
|
81
|
|
Central America
|
5
|
The top 20 Countries with the highest number of detected Cache Locations are:
|
Continent
|
Country
|
Detected Cache Instances
|
| North America |
United States |
296 |
| Asia |
Russia |
263 |
| South America |
Brazil |
220 |
| Asia |
India |
83 |
| North America |
Canada |
76 |
| North America |
Mexico |
70 |
| Europe |
United Kingdom |
67 |
| Asia |
Japan |
63 |
| Europe |
Ukraine |
59 |
| Asia |
Thailand |
51 |
| Oceania |
Australia |
48 |
| Europe |
Poland |
45 |
| Asia |
Indonesia |
38 |
| Europe |
Germany |
36 |
| South America |
Argentina |
31 |
| Oceania |
New Zealand |
27 |
| Europe |
Spain |
27 |
| Europe |
Italy |
27 |
| Europe |
France |
26 |
| Asia |
Bangladesh |
24 |
Top 25 Cities with the most Cache Locations detected:
| City |
Country |
Detected Cache Instances |
Detected Networks |
Ratio Networks/Caches |
| Moscow |
Russia |
42 |
918 |
21,9 |
| Sao Paulo |
Brazil |
31 |
740 |
23,9 |
| Tokyo |
Japan |
31 |
116 |
3,7 |
| Rio De Janeiro |
Brazil |
28 |
322 |
11,5 |
| Kiev |
Ukraine |
28 |
277 |
9,9 |
| London |
United Kingdom |
24 |
347 |
14,5 |
| Dhaka |
Bangladesh |
22 |
51 |
2,3 |
| Bangkok |
Thailand |
21 |
28 |
1,3 |
| St. Petersburg |
Russia |
18 |
102 |
5,7 |
| Sofia |
Bulgaria |
17 |
104 |
6,1 |
| Yekaterinburg |
Russia |
17 |
84 |
4,9 |
| Buenos Aires |
Argentina |
17 |
79 |
4,6 |
| Jakarta |
Indonesia |
17 |
28 |
1,6 |
| Bucharest |
Romania |
15 |
92 |
6,1 |
| Belgrade |
Serbia |
15 |
42 |
2,8 |
| Budapest |
Hungary |
14 |
123 |
8,8 |
| Sydney |
Australia |
14 |
54 |
3,9 |
| Mumbai |
India |
14 |
46 |
3,3 |
| Montreal |
Canada |
14 |
43 |
3,1 |
| Auckland |
New Zealand |
14 |
39 |
2,8 |
| Warsaw |
Poland |
13 |
318 |
24,5 |
| New York |
United States |
13 |
276 |
21,2 |
| Novosibirsk |
Russia |
13 |
76 |
5,8 |
| Toronto |
Canada |
13 |
71 |
5,5 |
| Kuala Lumpur |
Malaysia |
13 |
28 |
2,2 |
To give ourselves an idea of the number of users covered by our detected servers, we have ranked the 25 top countries in terms of the estimated number of users.
| Country |
Detected Cache Instances |
est. Number of Users |
Users/Cache |
| India |
83 |
236.000.000 |
2.845.000 |
| United States |
296 |
219.000.000 |
741.000 |
| Brazil |
220 |
105.000.000 |
478.000 |
| Japan |
63 |
93.000.000 |
1.478.000 |
| Russian Federation |
263 |
78.000.000 |
298.000 |
| Indonesia |
38 |
66.000.000 |
1.733.000 |
| Germany |
36 |
66.000.000 |
1.826.000 |
| Nigeria |
8 |
61.000.000 |
7.666.000 |
| Mexico |
70 |
61.000.000 |
870.000 |
| France |
26 |
52.000.000 |
2.000.000 |
| United Kingdom |
67 |
51.000.000 |
764.000 |
| Egypt |
13 |
45.000.000 |
3.455.000 |
| Philippines |
11 |
41.000.000 |
3.715.000 |
| Vietnam |
16 |
40.000.000 |
2.496.000 |
| Turkey |
1 |
35.000.000 |
35.212.000 |
| Spain |
27 |
34.000.000 |
1.271.000 |
| Italy |
27 |
34.000.000 |
1.268.000 |
| Bangladesh |
24 |
32.000.000 |
1.321.000 |
| Colombia |
22 |
30.000.000 |
1.375.000 |
| Argentina |
31 |
30.000.000 |
976.000 |
| Pakistan |
3 |
27.000.000 |
9.147.000 |
| South Africa |
14 |
23.000.000 |
1.642.000 |
| Poland |
45 |
22.000.000 |
500.000 |
| Kenya |
6 |
21.000.000 |
3.517.000 |
* Thanks to APNIC for helping us estimate the number of users in each network.
The following map pinpoints all the instances of Google Global Cache we could observe. Please remember that the pins are pointing to the cities’ airports and not their precise location within the city, which is close enough for describing their location for these purposes.
From the huge number of Probes we applied for the experiment, we got an impressive array of the variety of networks connected to each Cache Location.
When clicking on the pins, we can see a list of cache instances and below the corresponding list of connected networks to each cache.
Top 25 Cities with the most networks detected:
| City |
Country |
Cache Instances |
Detected Networks |
Ratio Networks/Caches |
| Moscow |
Russia |
42 |
918 |
21,9 |
| Sao Paulo |
Brazil |
31 |
740 |
23,9 |
| Chicago |
United States |
11 |
511 |
46,5 |
| Frankfurt |
Germany |
7 |
475 |
67,9 |
| Washington |
United States |
10 |
470 |
47,0 |
| Paris |
France |
12 |
405 |
33,8 |
| Amsterdam |
Netherlands |
8 |
383 |
47,9 |
| Dallas-Fort Worth |
United States |
9 |
356 |
39,6 |
| London |
United Kingdom |
24 |
347 |
14,5 |
| Rio De Janeiro |
Brazil |
28 |
322 |
11,5 |
| Warsaw |
Poland |
13 |
318 |
24,5 |
| Prague |
Czech Republic |
10 |
288 |
28,8 |
| Kiev |
Ukraine |
28 |
277 |
9,9 |
| New York |
United States |
13 |
276 |
21,2 |
| Los Angeles |
United States |
11 |
262 |
23,8 |
| Miami |
United States |
6 |
236 |
39,3 |
| Atlanta |
United States |
7 |
177 |
25,3 |
| San Jose |
United States |
3 |
159 |
53,0 |
| Milan |
Italy |
4 |
158 |
39,5 |
| Katowice |
Poland |
4 |
145 |
36,3 |
| Belo Horizonte |
Brazil |
12 |
131 |
10,9 |
| Madrid |
Spain |
9 |
125 |
13,9 |
| Budapest |
Hungary |
14 |
123 |
8,8 |
| Tokyo |
Japan |
31 |
116 |
3,7 |
| Mountain View |
United States |
2 |
109 |
54,5 |
We can observe, that there are locations with a high number of access points and also a high number of networks, but like in the case of Moscow or São Paulo, the relationship between the number of networks vs. number of access points is very high. A notable case is Tokyo, where 116 ISPs for 31 Cache Access Points were observed, giving a ratio of only 3,7.
It has to be taken into account that many access points are dedicated to different segments, for example, if we look at Berlin, Germany we will see that Vodafone and Telefonica Germany have their own dedicated access points (vodafone-ber1 and hansenet-ber2). On the other side, ber01s12 is probably owned by Deutsche Telekom AG, the biggest Telecom in Germany, which is giving access to other companies through their infrastructure, so we can see Verizon, Kabel Deutschland and also some other Telefonica users go through this other Access Point. Finally, if we observe ecix-ber1 we can see that that point seems to be reserved for Private Business ISPs, like e.discom, WEMACOM, the multimedia specialist MyWire or the private IT Infrastructure provider Macnetix.
Another important fact that has influence on the number of detected networks is our own coverage with ProbeAPI. In cases like Moscow, ProbeAPI has a high number of active probes in Russia, with Moscow having the highest concentration of them. That’s why this data has to be considered a snapshot of Google’s CDN taken with all our available probes at one particular time.
Following the same line, an interesting case is Turkey, where we could detect only one Cache Location, despite of having typically a high concentration of active Probes there. Turkey has been blocking access to Youtube and other Google services intermittently during the last years following political controversies, which could explain the low number of results obtained from a well covered region.
Conclusion
There is much mystery surrounding Google Global Cache which is one of Google’s most important pieces of infrastructure. We were able to gather an impressive number of information with one single measurement of ProbeAPI, which helped us to understand the extent and distribution of Google’s Cache Locations.
Taking into account that this information was made snapshot-like with one sole measurement, we gathered 2383 Cache Instances across 800 locations worldwide (at least) that Google is actively using throughout their partner network operators.
There are still some issues to be covered by more measurements over time which will surely reveal more networks and cache locations. This is one case where continuous monitoring will offer a good opportunity to get thorough measurements, not only in terms of traffic variability, but also in terms of coverage, as probes connect to ProbeAPI through different locations during any period of time.